우리는 최대한 밝게, 그러니까 최대한 매력적으로 우리는 자신을 상대방에게 알린다.
그러나 상대방이 우리 쪽으로 다가오든 아니면 다른 길을 선택하든 그것은 전적으로 상대방의 자유 의사에 맡겨야 한다.
우리는 상대방이 우리를 선택하든 말든 상관하지 말고 최대한 노력을 기울이면 된다.
다시 말해 강력하고 매력적인 빛을 비추기만 하면 된다.
2013년 11월 29일 금요일
지금..
인간은 항상 시간이 모자란다고 불평을 하면서 마치 시간이
무한정있는 것처럼 행동한다. - 세네카
변명 중에서도 가장 어리석고 못난 변명은
˝시간이 없어서˝라는 변명이다. - 에디슨
희망은 절대로 당신을 버리지 않는다.
다만 당신이 희망을 버릴 뿐이지.
- 리처드 브리크너 '망가진 날들' 中
새벽은 새벽에 눈뜬 자만이 볼 수 있다.
새벽이 오리라는 것을 알아도 눈을 뜨지 않으면
여전히 깊은 밤중일 뿐이다.
- 김수덕 ´새벽은 새벽에 눈뜬 자만이 볼 수 있다.´中
당신에게 가장 중요한 때와 당신에게 가장 중요한 일과
당신에게 가장 중요한 사람은 누구인지 아는가?
당신에게 가장 중요한 때는 지금 현재이며,
당신에게 가장 중요한 일은 지금 하고 있는 일이며
당신에게 가장 중요한 사람은 지금 만나고 있는 사람이다.
- 톨스토이
무한정있는 것처럼 행동한다. - 세네카
변명 중에서도 가장 어리석고 못난 변명은
˝시간이 없어서˝라는 변명이다. - 에디슨
희망은 절대로 당신을 버리지 않는다.
다만 당신이 희망을 버릴 뿐이지.
- 리처드 브리크너 '망가진 날들' 中
새벽은 새벽에 눈뜬 자만이 볼 수 있다.
새벽이 오리라는 것을 알아도 눈을 뜨지 않으면
여전히 깊은 밤중일 뿐이다.
- 김수덕 ´새벽은 새벽에 눈뜬 자만이 볼 수 있다.´中
당신에게 가장 중요한 때와 당신에게 가장 중요한 일과
당신에게 가장 중요한 사람은 누구인지 아는가?
당신에게 가장 중요한 때는 지금 현재이며,
당신에게 가장 중요한 일은 지금 하고 있는 일이며
당신에게 가장 중요한 사람은 지금 만나고 있는 사람이다.
- 톨스토이
2013년 11월 16일 토요일
사람을 설득하기위해 필요한 6가지
1. 상호성
2. 희귀성
3. 권위
4. 일관성
5. 호감
6. 사회적증거
1.상호성
give and take 방식으로 사람은 받으면 줘야한다는 심리를이용 간단한 선물을주고 (직접설득&무언의설득)을 하는대확률을높임
ex)레스토랑에서 팁을 받기전 사탕을 줌으로써 팁이 3%상승 2개를주니 14% 2개를주고 다시와서 손님칭찬+1개더 23% 상승
2.희귀성
사람들은 갖기힘든것을 더 갖고싶어한다.
ex)런던간여객기운행중단결정(이유:손님이없어 돈이안됨)->발표 후에 손닙급증
(얻는것+희귀성+얻지않을때 손실) -> 설득
3.권위
이분야에 전문가임을 알려줌 이때 직접 입으로말하는것보단 옷.자격증.트로피또는 제3자가 나에대해말해주는것들이효과가큼
ex)평상복을 입은사람과 제복을 입은 주차요원 둘에게서 제복을 입은쪽에게 <더> 순순히 돈을지불함
4.일관성
사람들은 과거에 예전에했던말에대해 일관성을보이려는 습성이있다.
일관성의 법칙이 성립하기이전에 작게라도 상대방이 개입되어야한다.
ex)집앞마당 안전운전표지판(어려운)설치좀요 A마을 4/20 B마을 18/20 why? -> B마을은 10일전 안전운전스티커부착부탁(쉬운)
5.호감
호감을 갖는사람에겐 yes확률이 높음
1.자신과비슷한사람 2.자신을 칭찬해주는사람 3.자신과 한가지목표를향해 같이 나아가는사람 에게 호감을느낌
ex)A그룹과B그룹이 있는데 A는 아무말없이 바로협상 B는 호감형성후 협상 ->a그룹 55% 성공 B그룹 90% 설득성공
6.사회적증거
사람들은 확신이없는경우 다른사람들의결정을보고 자신의의사를 결정한다
ex)마트에서 <일회용 봉투사용보단 장바구니 사용권장!!> 이푯말보다는
<우리마트는 장바구니를 사용하는 손님이 90%입니다. 일회용 봉투보단 장바구니사용을권장합니다.>
가 더효과적
1.상호성
give and take 방식으로 사람은 받으면 줘야한다는 심리를이용 간단한 선물을주고 (직접설득&무언의설득)을 하는대확률을높임
ex)레스토랑에서 팁을 받기전 사탕을 줌으로써 팁이 3%상승 2개를주니 14% 2개를주고 다시와서 손님칭찬+1개더 23% 상승
2.희귀성
사람들은 갖기힘든것을 더 갖고싶어한다.
ex)런던간여객기운행중단결정(이유:손님이없어 돈이안됨)->발표 후에 손닙급증
(얻는것+희귀성+얻지않을때 손실) -> 설득
3.권위
이분야에 전문가임을 알려줌 이때 직접 입으로말하는것보단 옷.자격증.트로피또는 제3자가 나에대해말해주는것들이효과가큼
ex)평상복을 입은사람과 제복을 입은 주차요원 둘에게서 제복을 입은쪽에게 <더> 순순히 돈을지불함
4.일관성
사람들은 과거에 예전에했던말에대해 일관성을보이려는 습성이있다.
일관성의 법칙이 성립하기이전에 작게라도 상대방이 개입되어야한다.
ex)집앞마당 안전운전표지판(어려운)설치좀요 A마을 4/20 B마을 18/20 why? -> B마을은 10일전 안전운전스티커부착부탁(쉬운)
5.호감
호감을 갖는사람에겐 yes확률이 높음
1.자신과비슷한사람 2.자신을 칭찬해주는사람 3.자신과 한가지목표를향해 같이 나아가는사람 에게 호감을느낌
ex)A그룹과B그룹이 있는데 A는 아무말없이 바로협상 B는 호감형성후 협상 ->a그룹 55% 성공 B그룹 90% 설득성공
6.사회적증거
사람들은 확신이없는경우 다른사람들의결정을보고 자신의의사를 결정한다
ex)마트에서 <일회용 봉투사용보단 장바구니 사용권장!!> 이푯말보다는
<우리마트는 장바구니를 사용하는 손님이 90%입니다. 일회용 봉투보단 장바구니사용을권장합니다.>
가 더효과적
2013년 10월 4일 금요일
BOSE QC20 사용기


BOSE QC20을 사기전 궁금한게 많아서 사용후기를 찾아보니
아직 출시된지 얼마 되지 않은제품이어서 그런지
국내 사용자가 적은 글은 몇개 없었다
해외 사용자들이 적은글들이 많아서 그나마 도움이 되었지만
제품에 관한 궁금한부분을 해소하기엔 아직 부족하다
인터넷을 보면 스펙과 숫자가 잔뜩 적혀있을뿐
사실 이게 실제 어떤느낌인지 체감하기가 어려운 부분들이 많다
이 제품을 사용하다 보니 인터넷에 잘 못 적혀 있는 것 도 있고 해서
사용하면서 느끼는점을 몇개 적어본다
사기전에는 케이블에 달린 저 배터리가 있는 모듈 부분이
이어폰을 사용할때 굉장히 거슬릴것 같았고 무게는 얼마나 될지가 궁금했는데
막상 사용하면서 불편하다 왜 이렇게 만들어 놨나 하는 부분은 없었다
저 모듈부분은 손가락 하나 길이에 가로길이는 손가락 두개를 합친 정도인데
주변 물건에 비교하자면
크기는 라이터 보다 조금 크고
두께는 갤럭시 노트 펜 두께정도에
무게는 일반 라이터 보다 좀더 가볍다
사진으론 굉장히 커보여서 거추장스러울것 같지만 사실 그렇진 않다
가장 중요했던 부분은 노이즈 캔슬링 기능인데
이어폰이기 때문에 헤드폰보다 성능이 떨어지진 않을지
본연의 성능을 얼마나 잘 뽑아낼수 있을지 이게 가장 궁금했었다
아무래도 이어폰이기 때문에 외부 소음이 쉽게 들어올까봐..
사용하면서 느낀점은 이게 커널형 이어폰이 아니기 때문에
이 이어폰을 착용한다고 해서 소음이 줄어들지는 않았다
커널형은 귀마개 처럼 귓구멍을 막아서 외부소음이 들어오지 않게끔 되어있지만
이 이어폰은 착용한상태와 착용하지 않은 소음상태가 똑같다
인터넷의 어떤글에 이걸 착용만 해도 소음이 조금 줄었다 라고 적힌 글을 본적이 있는데
이어폰을 착용한것과 착용하지 않은것의 소음의 차이는 거의 없다고 해도 무방할것같다
하지만
노이즈 캔슬링 기능을 켜면 주변이 조용해진다
QC3과 QC15 헤드폰을 사용했던 한사람으로써
두 헤드폰과 간락하게 비교를 하자면
헤드폰은 그 생김새로 인해 자체적인 외부소음을 차단하는 효과로
헤드폰 시리즈들이 주변을 더 조용하게 할 것 같은 생각을 갖게 하지만
QC20을 착용했을때가 더 조용하다
노이즈 캔슬링을 사용할때 주변 소음을 없애는 능력은
QC20 > QC15, QC3
노이즈 캔슬링 기능을 켜지 않았을때는 당연히 헤드폰이 더 조용하다
아무리 주변을 조용하게 만든다고 해서 인터넷에 적힌 글들처럼
자동차 소리가 안들리고 사람들 이야기 하는 소리가 안들리고
이런건 좀 과장섞인 표현같다
자동차 소리도 들리고 옆에서 뭐가 떨어지고 부딪히고 키보드 치는 소리가 들린다
하지만 이것도 구입한지 몇일 되지 않았을때나 느끼는 부분이다
물론 QC15, QC3 을 사용할때 들리는 소리보다는 조용하다
소리가 처음에 잘 들리는 이유는
노이즈 캔슬링 잘 작동하나? 이러면서 주변에 더 집중을 해서 그런것 같다
사용기간이 늘어나다 보면 정말 소리가 안들린다
하지만 나와 외부는 전혀 다른세계 라거나 내 귀에는 외부의 소리가 전혀 들리지 않아
이런정도는 아니다
처음 사용할때 홍보글에 속았나 싶었는데
이전에 사용하던 이어폰으로 바꿔서 사용해 보면서.. 아.. 아니구나 하는느낌을 받았다
비유를 하자면 SSD를 사서 컴퓨터를 처음 부팅할때
SSD 빠르다 그래서 샀는데, 하드랑 별로 차이도 안나네, 이거 괜히샀나?
이런생각 하다가 하드디스크를 다시 사용해보면 그제서야 느껴지는 속도감과 같다
노이즈 캔슬링을 처음 사용할땐 뭐야.. 이거 값어치도 못하네 이런생각 들다가
기존 이어폰, 헤드폰을 다시 사용하면 노이즈캔슬링 기술이 새삼 대단하다고 느끼게 된다
그뿐 아니라 노이즈 캔슬링 기능을 꺼버리면 주변이 얼마나 시끄러웠는지 알게된다
굉장히 조용한 곳에 가면 화이트노이즈도 있다
근데 조용한 곳에서는 노이즈 캔슬링을 켜고 이어폰을 사용하는게 더 이상한거다
왜 조용한곳에서 배터리를 사용하면서 노이즈캔슬링을???
전원을 꺼도 음악이 나오니 조용한곳에서는 배터리를 아끼자.
노이즈 캔슬링이 필요없는곳에서 화이트 노이즈 나온다고 이게 단점이다 할것은 아닌듯하다
이게 가장 큰 장점중 하나인데
다른 노이즈 캔슬링 제품들은 배터리를 모두 소모하게되면 음악 자체를 들을수가 없다
새로운 전원을 연결해 줄때까지는 짐이다.. 이게 굉장히 불편한 부분이다
하지만 이건 배터리가 없어도 음악을 들을수 있다. 노이즈 캔슬링 기능만 안될뿐..
이건 굉장히 좋은 장점이다
버튼도 굉장히 누르기 편하게 만들어져있다
겨울에 장갑을 껴도 버튼 누르는데 문제가 없을것같다
음질은 보스 스타일
저음이 너무 세지 않아서 음악 듣기에 편하다
=================================================================================
다음은 해외에서 측정한 QC20 그래프.
마지막 그래프가 압권!!!




NC off (green trace)
NC on (purple trace)
측정자가 지금까지 평가한 노이즈 캔슬링 제품중에
이만큼 그래프가 낮게 내려간 적이 없다고 표현
QC20은 노이즈 캔슬링의 최고
가장 성능이 좋은 노이즈 캔슬링 제품을 원한다면
QC15, QC3 보다 QC20
2013년 10월 1일 화요일
dssearch를 이용한 시퀀스에 연결된 잡 찾기
데이터 스테이지의 시퀀스 목록이 들어있는 파일을 읽는다
파일내용을 한줄씩 읽으면서 시퀀스에 연결된 작업을 표시
#!/bin/bash
path=/dshome/bin/dssearch
prj=project_name
source=list_file
target=target_file
prj=project_name
source=list_file
target=target_file
while read line
do
echo $line
echo $line >> $target
$path -ljobs -uses -r $prj $line >> $target
done < $source
do
echo $line
echo $line >> $target
$path -ljobs -uses -r $prj $line >> $target
done < $source
istool을 사용하여 데이터스테이지 잡 백업
istool을 사용하여 데이터스테이지 잡 백업
입력받은 숫자 -> 현재부터 몇일 이전을 구하기 위해 사용
ex) 3을 입력 받으면 현재보다 3일이전
5 는 5일 이전
#!/bin/sh
Today=`date + '%Y%m%d'` -> 오늘 날짜 구하는부분
Tdir="/home/whatever" -> 타겟 디렉터리
Sdir="Svr_name/project/*/*.*" -> 소스디렉터리
days=$1
num=`expr $1 \* 24 - 9` -> 9를 뺀 이유는 KST때문
local targetdate=`TZ=KST+num; date + '%Y%m%d'`
Tdir="/home/whatever" -> 타겟 디렉터리
Sdir="Svr_name/project/*/*.*" -> 소스디렉터리
days=$1
num=`expr $1 \* 24 - 9` -> 9를 뺀 이유는 KST때문
local targetdate=`TZ=KST+num; date + '%Y%m%d'`
if [-n $1 ]; -> 만약 숫자 입력값이 없으면 else에서 에러출력
then
...
X일 이전에 생성된 파일 검색후 삭제
find . -mtime +$days -exec rm -rf {} \;
...
Datastage istool 백업
/.../ds../Clients/istool export -domain domain -username username -password password -verbose -archive $Tdir{$Today}.isx -datastage $Sdir
then
...
X일 이전에 생성된 파일 검색후 삭제
find . -mtime +$days -exec rm -rf {} \;
...
Datastage istool 백업
/.../ds../Clients/istool export -domain domain -username username -password password -verbose -archive $Tdir{$Today}.isx -datastage $Sdir
else
...
fi
...
fi
2013년 9월 17일 화요일
우분투 설치후 root로 로그인하기
우분투는 설치하고 root 계정으로 접속 하려해도 되지 않는다
터미널을 띄우고
> sudo passwd root
새로운 비밀번호를 입력해 주고 나면 root로 로그인 가능
터미널을 띄우고
> sudo passwd root
새로운 비밀번호를 입력해 주고 나면 root로 로그인 가능
2013년 9월 16일 월요일

우분투 설치하고 xwindow 대신에 콘솔로 빠질때..
> sudo apt-get install xinit
> sudo apt-get update
> sudo apt-get upgrade
> sudo apt-get install ubuntu-desktop
모든과정 진행되고나면
> startx
> sudo apt-get update
> sudo apt-get upgrade
> sudo apt-get install ubuntu-desktop
모든과정 진행되고나면
> startx
2013년 9월 8일 일요일
Logitech trackball mouse - Trackman Marble 스크롤휠 설정 프로그램
다운로드는 여기 -> http://web.archive.org/web/20080619063152/http://simans.net/marble/
http://web.archive.org/web/20080619063152/http://simans.net/marble/marbleinst.exe
로지텍의 기본 프로그램인 set point 보다 훨씬 나은 프로그램
set point는 마우스의 휠처럼 사용하게끔 설정되어 있지 않지만
이 프로그램을 사용하면 휠처럼 사용할수 있다
오히려 마우스 휠보다 더 편하게 사용할 수 있다
로지텍의 기본 제공 프로그램인 set point를 삭제하고 위 프로그램을 설치
설치하고 나서 자기 편한대로 설정할 수 있지만
더 설정을 할필요가 없게끔 디폴트로 잘 되어있다
Windows 7 64bit ultimate K에서도 에러없이 정상 작동
http://web.archive.org/web/20080619063152/http://simans.net/marble/marbleinst.exe
로지텍의 기본 프로그램인 set point 보다 훨씬 나은 프로그램
set point는 마우스의 휠처럼 사용하게끔 설정되어 있지 않지만
이 프로그램을 사용하면 휠처럼 사용할수 있다
오히려 마우스 휠보다 더 편하게 사용할 수 있다
로지텍의 기본 제공 프로그램인 set point를 삭제하고 위 프로그램을 설치
설치하고 나서 자기 편한대로 설정할 수 있지만
더 설정을 할필요가 없게끔 디폴트로 잘 되어있다
Windows 7 64bit ultimate K에서도 에러없이 정상 작동
2013년 6월 5일 수요일
데이터 이상과 정규화
삭제 이상 - 한 투플을 삭제함으로써 유지해야 될 정보까지도 삭제되는 연쇄삭제 현상이 일어나게 되어 정보손실이 발생하게되는것
삽입이상 - 어떤 데이타를 삽입 하려고 할 때 불필요하고 원하지 않는 데이타도 함께 삽입해야만 되고 그렇지 않으면 삽입이 되지 않는 현상
갱신이상 - 중복된 투플들 중에서 일부 투플의 애트리뷰트 값만을 갱신시킴으로써 정보의 모순성이 생기는 현상
위와 같은 이상들이 일어나는 근본적인 이유는 여러가지 상이한 종류의 정보를 하나의 릴레이션으로 표현하려 하기 때문. 즉, 애트리뷰트들 간에 존재하는 여러 가지 데이타 종속 관계를 무리하게 하나의 릴레이션으로 표현하려는 데서 이런 이상들이 발생
정규화 - 애트리뷰트들 간의 종속성을 분석해서 하나의 릴레이션에는 기본적으로 하나의 종속성이 표현되도록 분해하는 과정
삽입이상 - 어떤 데이타를 삽입 하려고 할 때 불필요하고 원하지 않는 데이타도 함께 삽입해야만 되고 그렇지 않으면 삽입이 되지 않는 현상
갱신이상 - 중복된 투플들 중에서 일부 투플의 애트리뷰트 값만을 갱신시킴으로써 정보의 모순성이 생기는 현상
위와 같은 이상들이 일어나는 근본적인 이유는 여러가지 상이한 종류의 정보를 하나의 릴레이션으로 표현하려 하기 때문. 즉, 애트리뷰트들 간에 존재하는 여러 가지 데이타 종속 관계를 무리하게 하나의 릴레이션으로 표현하려는 데서 이런 이상들이 발생
정규화 - 애트리뷰트들 간의 종속성을 분석해서 하나의 릴레이션에는 기본적으로 하나의 종속성이 표현되도록 분해하는 과정
2013년 6월 2일 일요일
vi 명령어
한국어버전 출처 : http://kldp.org/node/102947
원본 : http://www.viemu.com/에서 제공하는 Graphical vi-vim Cheat Sheet and Tutorial








원본 : http://www.viemu.com/에서 제공하는 Graphical vi-vim Cheat Sheet and Tutorial
2013년 5월 21일 화요일
DDL, DML, DCL
DDL(Data Definition Language)
• DB 구조를 정의하거나 그 정의를 수정할 목적으로
사용하는 언어
• 데이터 사전, 시스템 카탈로그에 저장하여 놓고 필요한 경우에
시스템에 활용
• 객체의 생성,변경,삭제 명령어
Ø CREATE – Schema,
Domain, Table, View, Index를 정의함
Ø ALTER – 테이블에 대한 정의를 변경하는데 사용
Ø DROP – Schema, Domain, Table, View, Index를 삭제(테이블 전체 삭제, rollback 불가)
Ø TRUNCATE
– 자료버림(테이블 구조만 남기고 삭제, rollback 불가)
Ø COMMENT
- 주석
Ø RENAME - 데이터베이스 컬럼명 변경
vDDL 명령은 Autocommit 이라 한번 수행하면 되돌릴 수 없다
v데이터베이스 관리자나 데이터베이스 설계자가 사용
DML(Data Manipulaition Language)
• DB의 정보에 접근하기위한 목적으로 사용하는 언어
• 절차적 DML(한번에 하나의 레코드)과 비절차적 DML(set 단위 레코드)이 있다
• 레코드 제어 명령어 – 데이터의 검색, 수정, 삭제등을 처리
Ø SELECT – 테이블에서 조건에 맞는 튜플을 검색
Ø INSERT – 테이블에 새로운 튜플을 삽입
Ø UPDATE – 테이블의 조건에 맞는 튜플의 내용을 변경
Ø DELETE – 테이블에서 조건에 맞는 튜플을 삭제(rollback 가능)
Ø MERGE
Ø CALL
ØEXPLAIN PLAN
ØLOCK TABLE
• TCL – Transaction Control Language(DML 작업중 변경사항 제어)
Ø Commit – 작업후 저장
Ø Rollback – 마지막 commit 된 지점으로 복구
Ø Savepoint – 복구지점 생성
v데이터베이스 사용자가 응용프로그램이나 질의어를 통하여 저장된 데이터를 실질적으로 처리하는데 사용하는 언어
v데이터베이스 사용자와 데이터베이스 관리 시스템간의 인터페이스 제공
DCL(Data Control Language)
• 보안, 무결성, 회복, 병행제어
• 데이터베이스 사용자의 권한 제어
Ø GRANT – 일련의 권한 부여
Ø REVOKE – 일련의 권한 취소
[펌] Windows에서 글꼴 설치 또는 제거하는 방법
출처 - http://support.microsoft.com/kb/314960/ko
이 문서는 Microsoft Windows 95, Microsoft Windows 98 및 Microsoft Windows 98 Second Edition에 대한 기술 자료 문서 130233을 대체합니다.
이 문서에서는 Microsoft Windows에서 글꼴을 추가하고 제거하는 방법을 설명합니다.
참고 컴퓨터에서 Windows NT 4.0, Windows 2000, Windows XP 또는 Windows Server 2003이 실행되는 경우 글꼴을 추가하거나 제거하기 위해서는 관리자여야 합니다. 컴퓨터 관리자의 사용자 계정으로 Windows에 로그온했는지 확인하려면, 다음 Microsoft 웹 사이트를 참조하십시오.
중요 글꼴을 설치하려면 해당 글꼴이 플로피 디스크, CD 또는 하드 디스크에 들어 있어야 합니다.
글꼴을 설치하려면 다음과 같이 하십시오.
이 문서는 Microsoft Windows 95, Microsoft Windows 98 및 Microsoft Windows 98 Second Edition에 대한 기술 자료 문서 130233을 대체합니다.
이 문서에서는 Microsoft Windows에서 글꼴을 추가하고 제거하는 방법을 설명합니다.
참고 컴퓨터에서 Windows NT 4.0, Windows 2000, Windows XP 또는 Windows Server 2003이 실행되는 경우 글꼴을 추가하거나 제거하기 위해서는 관리자여야 합니다. 컴퓨터 관리자의 사용자 계정으로 Windows에 로그온했는지 확인하려면, 다음 Microsoft 웹 사이트를 참조하십시오.
새 글꼴 추가
참고 표준 Windows 글꼴을 다시 설치하려면 "Windows에 포함된 표준 글꼴 다시 설치" 절로 이동하십시오.중요 글꼴을 설치하려면 해당 글꼴이 플로피 디스크, CD 또는 하드 디스크에 들어 있어야 합니다.
글꼴을 설치하려면 다음과 같이 하십시오.
- 시작을 클릭하고 실행을 클릭합니다.
- 다음 명령을 입력한 다음 확인을 클릭합니다.%windir%\fonts
- 파일 메뉴에서 새 글꼴 설치를 클릭합니다.
- 드라이브 상자에서 추가할 글꼴이 있는 드라이브를 클릭합니다.
참고 플로피 디스크 드라이브는 일반적으로 드라이브 A 또는 드라이브 B입니다. CD 드라이브는 일반적으로 드라이브 D입니다. - 폴더 상자에서 추가하려는 글꼴이 들어 있는 폴더를 클릭하고확인을 클릭합니다.
- 글꼴 목록 상자에서 추가할 글꼴을 클릭합니다. 한 번에 둘 이상의 글꼴을 선택하려면 Ctrl 키를 누른 채로 각 글꼴을 선택합니다.
- Fonts 폴더에 글꼴 복사 확인란을 클릭하여 선택합니다. 새 글꼴이 Windows\Fonts 폴더에 저장됩니다.
- 확인을 클릭합니다.
글꼴 제거
하드 디스크에서 글꼴을 제거하려면 다음과 같이 하십시오.- 시작을 클릭하고 실행을 클릭합니다.
- 다음 명령을 입력한 다음 확인을 클릭합니다.%windir%\fonts
- 제거할 글꼴을 클릭합니다. 한 번에 둘 이상의 글꼴을 선택하려면 Ctrl 키를 누른 채로 각 글꼴을 선택합니다.
- 파일 메뉴에서 삭제를 클릭합니다.
- "이 글꼴을 삭제하시겠습니까?" 프롬프트가 나타나면 예를 클릭합니다.
기술 자료: 314960 - 마지막 검토: 2013년 4월 26일 금요일 - 수정: 1.0
본 문서의 정보는 다음의 제품에 적용됩니다.
- Microsoft Windows Server 2003, Enterprise Edition (32-bit x86)
- Microsoft Windows Server 2003, Datacenter Edition (32-bit x86)
- Microsoft Windows Server 2003, Standard Edition (32-bit x86)
- Microsoft Windows Server 2003, Web Edition
- Microsoft Windows Server 2003, Enterprise x64 Edition
- Microsoft Windows XP Professional
- Microsoft Windows XP Home Edition
- Microsoft Windows XP Tablet PC Edition
- Microsoft Windows XP Media Center Edition 2005 Update Rollup 2
- Microsoft Windows 2000 Advanced Server
- Microsoft Windows 2000 Professional Edition
- Microsoft Windows 2000 Server
- Microsoft Windows NT Server 4.0 Standard Edition
- Microsoft Windows NT Workstation 4.0 Developer Edition
2013년 4월 19일 금요일
[펌] NESTED LOOP JOIN, SORT MERGE JOIN, HASH JOIN 정리
[출처] http://zoonoo.egloos.com/2272248
1. NESTED LOOP JOIN
NESTED LOOP JOIN이란 먼저 선행테이블(Driving Table)의 처리범위를 하나씩 액세스하면서 그 추출된 값으로 연결할 테이블을 조인하는 방식이다.
따라서 선행테이블의 결정과 처리범위에 따라 성능이 좌우된다.
HINT: /*+ use_nl (테이블) */
[특징]
- 순차적으로 처리된다. 선행테이블의 처리범위에 있는 각각의 로우들이 순차적으로 수행될 뿐만 아니라 테이블간의 연결도 순차적이다.
- 먼저 액세스되는 테이블(Driving Table)의 처리범위에 의해 처리량이 결정된다
- 나중에 처리되는 테이블은 앞서 처리된 값을 받아 액세스된다. 즉, 자신에게 주어진 상수값에 의해 스스로 범위를 줄이는 것이 아니라 값을 받아서 처리범위가 정해진다.
- 주어진 조건에 있는 모든 컬럼들이 인덱스를 가지고 있더라도 모두가 사용되는 것은 아니다. 연결되는 방향에 따라 사용되는 인덱스들이 전혀 달라질 수 있다.
- 연결고리의 인덱스 유무에 따라 액세스 방향 및 수행속도에 많은 차이가 발생된다.
[사용기준]
- 부분범위처리를 하는 경우에 주로 유리해진다.
- 조인되는 어느 한쪽이 상대방 테이블에서 추출된 결과를 받아야 처리범위를 줄일 수 있는 상태라면 항상 유리해진다.
- 주로 처리량이 적은 경우(많더라도 부분범위처리가 가능한 경우)에 유리해진다. 그것은 처리방식이 주로 랜덤 액세스방식이므로 많은 양의 랜덤 액세스가 발생한다면 수행속도가 당연히 나빠지기 때문이다.
- 순차적으로 처리되기 때문에 어떤 테이블이 먼저 액세스되느냐에 따라 수행속도에 많은 영향을 미치므로 최적의 액세스 순서가 되도록 적절한 조치가 요구된다.
- 선행테이블의 처리 범위가 많거나 연결 테이블의 랜덤 액세스의 양이 아주 많다면 SORT MERGE JOIN보다 불리해지는 경우가 많다.
- 일반적으로 온라인 어플리케이션에 유리하다.
2. SORT MERGE JOIN
SORT MERGE JOIN이란 양쪽 테이블의 처리범위를 각자 액세스하여 정렬한 결과를 차례로 스캔하면서 연결고리의 조건으로 머지해 가는 방식을 말한다. 이 방식은 경우에 따라 Nested Loop Join보다 훨씬 빨라지는 경우도 많이 있으며 랜덤 액세스가 줄어들어 시스템의 부하를 감소시키지만 일반적으로 NESTED LOOP JOIN 보다는 사용되는 빈도가 적은 편이다.
이 방식의 가장 큰 특징은 상대방에게 아무런 값도 받지 않고 자신이 가지고 있는 조건만으로 처리범위가 정해지며, 랜덤 액세스를 줄일 수는 있으나 항상 전체범위처리를 한다는 것이다.
HINT: /*+ use_merge(테이블) */
[특징]
- 동시적으로 처리된다. 테이블 각자가 자신의 처리범위를 액세스하여 정렬해 둔다.
- 결코 부분범위처리를 할 수가 없으며, 항상 전체범위처리를 한다.
- 주로 스캔방식으로 처리된다. 자신의 처리범위를 줄이기 위해 인덱스를 사용하는 경우만 랜덤 액세스이고 머지작업은 스캔방식이다.
- 주어진 조건에 있는 모든 컬럼들이 인덱스를 가지고 있더라도 모두가 사용되는 것은 아니다. 연결고리가 되는 컬럼은 인덱스를 전혀 사용하지 않는다.
- 조인의 방향과는 전혀 무관하다.
- 스스로 자신의 처리범위를 줄이기 위해 사용되는 인덱스는 대개 가장 유리한 한가지만 사용되어진다. 그러나 그 외의 조건들은 비록 인덱스를 사용하지 못하더라도 작업대상을 줄여 주기 때문에 중요한 의미를 가진다.
[사용기준]
- 전체범위처리를 하는 경우에 주로 유리해진다.
- 상대방 테이블에서 어떤 상수값을 받지 않고도 처리범위를 줄일 수 있는 상태인 경우 주로 유리해 질 수 있다. 상수값을 받아 처리(NESTED LOOP JOIN)한 범위의 크기와 처리범위를 줄여 처리(SORT MERGE JOIN)한 범위의 크기를 대비해보아 상수값을 받아 줄여진 범위가 약 30% 이상이라면 SORT MERGE JOIN이 일반적으로 유리해진다. 그러나 부분범위처리가 되는 경우라면 전혀 달라질 수 있다. 이런 경우는 처리할 전체범위를 비교하지 말고 첫번째 운반단위에 도달하기 위해 액세스하는 범위애 대해서 판단해야 한다.
- 주로 처리량이 많은 경우 (항상 전체범위처리를 해야 하는 경우)에 유리해진다. 그것은 처리방식이 주로 스캔방식이므로 많은 양의 랜덤 액세스를 줄일 수가 있기 때문이다.
- 스스로 자신의 처리범위를 어떻게 줄일 수 있느냐가 수행속도에 많은 영향을 미치므로 보다 효율적으로 액세스할 수 잇는 인덱스 구성이 중요한다.
- 처리할 데이터량이 적은 온라인 애플리케이션에서는 NESTED LOOP JOIN이 유리한 경우가 많으므로 함부로 SORT MERGE JOIN을 사용하지 말아야 한다.
- 일반적으로 배치작업시 유리하다.
3. HASH JOIN
해시값을이용하여 테이블을 조인하는 방식이다.
HINT: /*+ use_hash(테이블) */
- 적은테이블과 큰테이블의 조인시에 유리하다.
- Equal 조인에서만 가능하다.
- 선행테이블에 인덱스를 필요로 하지 않고 각 테이블을 한번만 읽음
- 다른조인방법보다 CPU자원을 많이 소비하며 양쪽 테이블의 스켄이 동시에 일어남.
1. NESTED LOOP JOIN
NESTED LOOP JOIN이란 먼저 선행테이블(Driving Table)의 처리범위를 하나씩 액세스하면서 그 추출된 값으로 연결할 테이블을 조인하는 방식이다.
따라서 선행테이블의 결정과 처리범위에 따라 성능이 좌우된다.
HINT: /*+ use_nl (테이블) */
[특징]
- 순차적으로 처리된다. 선행테이블의 처리범위에 있는 각각의 로우들이 순차적으로 수행될 뿐만 아니라 테이블간의 연결도 순차적이다.
- 먼저 액세스되는 테이블(Driving Table)의 처리범위에 의해 처리량이 결정된다
- 나중에 처리되는 테이블은 앞서 처리된 값을 받아 액세스된다. 즉, 자신에게 주어진 상수값에 의해 스스로 범위를 줄이는 것이 아니라 값을 받아서 처리범위가 정해진다.
- 주어진 조건에 있는 모든 컬럼들이 인덱스를 가지고 있더라도 모두가 사용되는 것은 아니다. 연결되는 방향에 따라 사용되는 인덱스들이 전혀 달라질 수 있다.
- 연결고리의 인덱스 유무에 따라 액세스 방향 및 수행속도에 많은 차이가 발생된다.
[사용기준]
- 부분범위처리를 하는 경우에 주로 유리해진다.
- 조인되는 어느 한쪽이 상대방 테이블에서 추출된 결과를 받아야 처리범위를 줄일 수 있는 상태라면 항상 유리해진다.
- 주로 처리량이 적은 경우(많더라도 부분범위처리가 가능한 경우)에 유리해진다. 그것은 처리방식이 주로 랜덤 액세스방식이므로 많은 양의 랜덤 액세스가 발생한다면 수행속도가 당연히 나빠지기 때문이다.
- 순차적으로 처리되기 때문에 어떤 테이블이 먼저 액세스되느냐에 따라 수행속도에 많은 영향을 미치므로 최적의 액세스 순서가 되도록 적절한 조치가 요구된다.
- 선행테이블의 처리 범위가 많거나 연결 테이블의 랜덤 액세스의 양이 아주 많다면 SORT MERGE JOIN보다 불리해지는 경우가 많다.
- 일반적으로 온라인 어플리케이션에 유리하다.
2. SORT MERGE JOIN
SORT MERGE JOIN이란 양쪽 테이블의 처리범위를 각자 액세스하여 정렬한 결과를 차례로 스캔하면서 연결고리의 조건으로 머지해 가는 방식을 말한다. 이 방식은 경우에 따라 Nested Loop Join보다 훨씬 빨라지는 경우도 많이 있으며 랜덤 액세스가 줄어들어 시스템의 부하를 감소시키지만 일반적으로 NESTED LOOP JOIN 보다는 사용되는 빈도가 적은 편이다.
이 방식의 가장 큰 특징은 상대방에게 아무런 값도 받지 않고 자신이 가지고 있는 조건만으로 처리범위가 정해지며, 랜덤 액세스를 줄일 수는 있으나 항상 전체범위처리를 한다는 것이다.
HINT: /*+ use_merge(테이블) */
[특징]
- 동시적으로 처리된다. 테이블 각자가 자신의 처리범위를 액세스하여 정렬해 둔다.
- 결코 부분범위처리를 할 수가 없으며, 항상 전체범위처리를 한다.
- 주로 스캔방식으로 처리된다. 자신의 처리범위를 줄이기 위해 인덱스를 사용하는 경우만 랜덤 액세스이고 머지작업은 스캔방식이다.
- 주어진 조건에 있는 모든 컬럼들이 인덱스를 가지고 있더라도 모두가 사용되는 것은 아니다. 연결고리가 되는 컬럼은 인덱스를 전혀 사용하지 않는다.
- 조인의 방향과는 전혀 무관하다.
- 스스로 자신의 처리범위를 줄이기 위해 사용되는 인덱스는 대개 가장 유리한 한가지만 사용되어진다. 그러나 그 외의 조건들은 비록 인덱스를 사용하지 못하더라도 작업대상을 줄여 주기 때문에 중요한 의미를 가진다.
[사용기준]
- 전체범위처리를 하는 경우에 주로 유리해진다.
- 상대방 테이블에서 어떤 상수값을 받지 않고도 처리범위를 줄일 수 있는 상태인 경우 주로 유리해 질 수 있다. 상수값을 받아 처리(NESTED LOOP JOIN)한 범위의 크기와 처리범위를 줄여 처리(SORT MERGE JOIN)한 범위의 크기를 대비해보아 상수값을 받아 줄여진 범위가 약 30% 이상이라면 SORT MERGE JOIN이 일반적으로 유리해진다. 그러나 부분범위처리가 되는 경우라면 전혀 달라질 수 있다. 이런 경우는 처리할 전체범위를 비교하지 말고 첫번째 운반단위에 도달하기 위해 액세스하는 범위애 대해서 판단해야 한다.
- 주로 처리량이 많은 경우 (항상 전체범위처리를 해야 하는 경우)에 유리해진다. 그것은 처리방식이 주로 스캔방식이므로 많은 양의 랜덤 액세스를 줄일 수가 있기 때문이다.
- 스스로 자신의 처리범위를 어떻게 줄일 수 있느냐가 수행속도에 많은 영향을 미치므로 보다 효율적으로 액세스할 수 잇는 인덱스 구성이 중요한다.
- 처리할 데이터량이 적은 온라인 애플리케이션에서는 NESTED LOOP JOIN이 유리한 경우가 많으므로 함부로 SORT MERGE JOIN을 사용하지 말아야 한다.
- 일반적으로 배치작업시 유리하다.
3. HASH JOIN
해시값을이용하여 테이블을 조인하는 방식이다.
HINT: /*+ use_hash(테이블) */
- 적은테이블과 큰테이블의 조인시에 유리하다.
- Equal 조인에서만 가능하다.
- 선행테이블에 인덱스를 필요로 하지 않고 각 테이블을 한번만 읽음
- 다른조인방법보다 CPU자원을 많이 소비하며 양쪽 테이블의 스켄이 동시에 일어남.
2013년 3월 16일 토요일
협상의 룰, 난 어떤 사람이 되어야 하는가
큰 협상을 하려면 거침없이 한치도 두려움 없이 원하는 것을 묻고 또 물어야 한다
협상원칙 - 품질좋은 제품을 먼저 갖추고, 우리의 스토리를 한 치 오차도 없이 상대방에게 정확히 전달하며, 마지막으로 '우리 가치가 이 정도나 되니 더 돈을 받아야 되겠다' 고 부끄럼 없이 당당하게 요구하는것
다른 사람이 원하는 당신이 되면 안된다
직장에서 최고가 되려면 당신의 상사를 빛나게 하세요
- 그가 나오기 전에 출근하고 그가 퇴근하기 전까지 가지 말고 그를 어떻게 도울 수 있을까 생각하세요
협상은 꾀를 부리지 말고 단순하게
매우 강력한 의견을 가지되 자존심은 버리고 토론
실패를 포용하라
2013년 2월 26일 화요일
SQL 전문가 가이드 2장 2절~4절 집합연산자
2절 집합 연산자(SET OPERATOR)
두개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법중에 또 다른 방법이 있는데 그 방법이 바로 집합연산자를 사용하는 방법이다. 조인에서는 FROM절에 검색하고자 하는 테이블을 나열하고, WHERE 절에 조인 조건을 기술하여 원하는 데이터를 조회할 수 있었다. 하지만 집합 연산자는 여러 개의 질의의 결과를 연결하여 하나로 결합하는 방식을 사용한다. 즉 집합연산자는 2개 이상의 질의 결과를 하나의 결과로 만들어 준다.
집합연산자를 사용하기 위해서는 다음 제약조건을 만족해야 한다. SELECT 절의 칼럼수가 동일하고 SELECT 절의 동일 위치에 존재하는 칼럼의 데이터 타입이 상호 호환가능해야 한다. 그렇지 않으면 데이터베이스가 오류를 반환.
집합 연산자의 종류
- UNION : 여러 개의 SQL 문의 결과에 대한 합집합으로 결과에서 모든 중복된 행은 하나의 행으로 만든다.
- UNION ALL : 여러 개의 SQL 문의 결과에 대한 합집합으로 중복된 행도 그대로 결과로 표시된다. 즉, 단순히 결과만 합쳐놓은 것이다. 일반적으로 여러 질의 결과가 상호 배타적인 일때 많이 사용한다. 개별 SQL 문의 결과가 서로 중복되지 않는 경우, UNION과 결과가 동일 하다.
- INTERSECT : 여러 개의 SQL 문의 결과에 대한 교집합이다. 중복된 행은 하나의 행으로 만든다.
- EXCEPT : 앞의 SQL 문의 결과에서 뒤의 SQL 문의 결과에 대한 차집합이다. 중복된 행은 하나의 행으로 만든다.
집합연산자는 개별 SQL문의 결과 집합에 대해 합집합, 교집합, 차집합으로 집합간의 관계를 가지고 작업을 한다.

집합연산자는 사용상의 제약조건을 만족한다면 어떤 형태의 SELECT문이라도 이용할 수 있다. 집합연산자는 여러개의 SELECT 문을 연결하는 것에 지나지 않는다. ORDER BY는 집합 연산을 적용한 최종결과에 대한 정렬처리이므로 가장 마지막 줄에 한번만 기술한다.
3절 계층형 질의와 셀프 조인
1. 계층형 질의
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의(HIREARCHICAL QUERY)를 사용한다. 계층형 데이터란 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터를 말한다. 예를 들어, 사원 테이블에서는 사원들 사이에 상위 사원(관리자)과 하위 사원 관계가 존재하고 조직 테이블에서는 조직들 사이에 상위 조직과 하위 조직 관계가 존재한다. 엔터티를 순환관계 데이터 모델로 설계할 경우 계층형 데이터가 발생한다. 순환관계 데이터 모델의 예로는 조직, 사원, 메뉴 등이 있다.

위 그림은 사원에 대한 순환관계 데이터 모델을 표현한 것이다. (2)계층형 구조에서 A의 하위 사원은 B, C이고 B 밑에는 사위 사원이 없고 C의 하위 사원은 D, E가 있다. 계층형 구조를 데이터로 표현한 것이 (3) 샘플 데이터 이다.
오라클은 계층형 질의를 지원하기 위해서 다름과 같은 계층형 질의 구문을 제공한다.
SELECT ...
FROM 테이블
WHERE condition AND condition...
START WITH condition
CONNECT BY [NOCYCLE] condition AND condition...
[ORDER SIBLINGS BY column, column, ...]
- START WITH 절은 계층 구조 전개의 시작 위치를 지정하는 구문이다. 즉 루트 데이터를 지정한다.
- CONNECT BY 절은 다음에 전개될 자식 데이터를 지정하는 구문이다. 자식 데이터는 CONNECT BY 절에 주어진 조건을 만족해야 한다.(조인)
-PRIOR : CONNECT BY 절에 사용되며, 현재 읽은 칼럼을 지정한다. PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 부모 데이터에서 자식데이터 (부모 -> 자식) 방향으로 전개하는 순방향 전개를 한다. 그리고 PRIOR 부모 = 자식 형태를 사용하면 반대로 자식 데이터에서 부모데이터 (자식 -> 부모) 방향으로 전개하는 역방향 전개를 한다.
- NOCYCLE : 데이터를 전개하면서 이미 나타났던 동일한 데이터가 전개 중에 다시 나타난다면 이것을 가리켜 사이틀이 형성되었다라고 말한다. 사이클이 발생한 데이터는 런타임 오류가 발생한다. 그렇지만 NOCYCLE를 추가하면 사이클이 발생한 이후의 데이터는 전개하지 않는다.
- ORDER SIBLINGS BY : 형제 노드(동일 LEVEL) 사이에서 절렬을 수행한다.
- WHERE : 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출한다. (필터링)
ORACLE 은 계층형 질의를 사용할 때 다음과 같은 가상칼럼(PSUDO COLUMN)을 제공한다.

2. 셀프조인
셀프조인이란 동일 테이블 사이의 조인을 말한다. 따라서 FROM절에 동일 테이블이 두 번 이상 나타난다. 동일 테이블 사이의 조이능ㄹ 수행하면 테이블과 칼럼 이름이 모두 동일하기 때문에 식별을 위해 반드시 테이블 별칭을 사용해야 한다. 그리고 칼럼에도 모두 테이블 별칭을 사용해서 어느 테이블의 칼럼인지 식별해줘야 한다. 이외 사항은 조인과 동일하다.
셀프 조인에 대한 기본적인 사용법은 다음과 같다.
계층형 질의에서 살펴보았던 사원이라는 테이블 속에는 사원과 관리자가 모두 하나의 사원이라는 개념으로 동일시하여 같이 입력되어 있다. 이것을 이용해서 다음 문제를 셀프 조인으로 해결해 보면 다음과 같다. "자신과 상위, 차상위 관리자를 같은 줄에 표시하라." 이 문제를 해결하기 위해서는 FROM 절에 사원 테이블을 두 번 사용해야 한다.

셀프 조인은 동일한 테이블 이지만 위 그림과 같이 개념적으로는 두 개의 서로 다른 테이블을 사용하는 것과 동일하다. 동일 테이블을 다른 테이블인 것처럼 처리하기 위해 테이블 별칭을 사용한다. 여기서는 E1, E2 테이블 별칭을 사용하였다. 차상위 관리자를 구하기 위해서 E1.관리자 = E2.사원 조건을 사용한다.
4절 서브쿼리
서브쿼리란 하나의 sql문 안에 포함되어 있는 또 다른 sql문을 말하낟. 서브쿼리는 알려지지 않은 기준을 이용한 검색을 위해 사용하낟. 서브쿼리는 다음그림과 같이 메인 쿼리가 서브 쿼리를 포함하는 종속적인 관계이다.
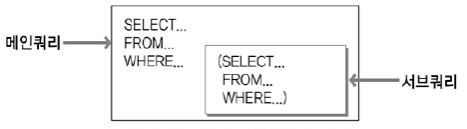
조인은 조인에 참여하는 모든 테이블이 대등한 관계에 있기 때문에 조인에 참여하는 모든 테이블의 칼럼을 어느 위치에서라도 자유롭게 사용할 수 있다. 그러나 서브쿼리는 메인쿼리의 칼럼을 모두 사용할 수 있지만 메인쿼리는 서브쿼리의 칼럼을 사용할 수 없다. 질의 결과에 서브쿼리 칼럼을 표시해야 한다면 조인 방식으로 변환하거나 함수, 스칼라 서브쿼리 등을 사용해야 한다.
조인은 집합간의 곱의 관계이다. 즉, 1:1 관계의 테이블이 조인하면 1(=1*1)레벨의 집합이 생성되고, 1:M 관계의 테이블을 조인하면 M(=1*M)레벨의 집합이 생성된다. 그리고 M:N 관계의 테이블을 조인하면 MN(=M*N) 레벨의 집합이 결과로서 생성된다. 예를 들어 조직(1)과 사원(M) 테이블을 조인하면 결과는 사원레벨(M)의 집합이 생성된다. 그러나 서브쿼리는 서브쿼리 레벨과는 상관없이 항상 메인쿼리 레벨로 결과 집합이 생성된다. 예를 들어, 메인쿼리로 조직(1), 서브쿼리로 사원(M) 테이블을 사용하면 결과집합은 조직(1) 레벨이 된다.
SQL 문에서 서브쿼리 방식을 사용해야 할 때 잘못 판단하여 조인 방식을 사용하는 경우가 있다. 예를들어, 결과는 조직 레벨이고 사원테이블에서 체크해야 할 조건이 존재한다고 가정하다. 이런 상황에서 SQL 문을 작성할 때 조인을 사용한다면 결과 집합은 사원(M) 레벨이 될 것이다. 이렇게 되면 원하는 결과가 아니기 때문에 SQL 문에 DISTINCT를 추가해서 결과를 다시 조직(1) 레벨로 만든다. 이와같은 상황에서는 조인 방식이 아니라 서브쿼리 방식을 사용해야 한다. 메인쿼리로 조직을 사용하고 서브쿼리로 사원 테이블을 사용하면 결과 집합은 조직레벨이 되기 때문에 원하는 결과가 된다.
서브쿼리를 사용할 때 다음 사항에 주의해야 한다.
1. 서브쿼리를 괄호로 감싸서 사용한다.
2. 서브쿼리는 단일행 또는 복수행 비교 연산자와 함께 사용 가능하다. 단일행 비교 연산자는 서브쿼리의 결과가 반드시 1건 이하이어야 하고 복수 행 비교 연산자는 서브쿼리의 결과 건수와 상관없다.
3. 서브쿼리에서는 ORDER BY를 사용하지 못한다. ORDER BY 적은 SELECT절에서 오직 한 개만 올 수 있기 때문에 ORDER BY절은 메인 쿼리의 마지막 문장에 위치해야 한다.
서브쿼리가 SQL 문에서 사용이 가능한 곳은 다음과 같다.
- SELECT 절
- FROM 절
- WHERE 절
- HAVING 절
- ORDER BY 절
- INSERT문의 VALUES 절
- UPDATE 문의 SET 절
서브쿼리의 종류는 동작하는 방식이나 반환되는 데이터의 형태에 따라 분류할 수 있다. 동작하는 방식에 따라 서브쿼리를 분류하면 다음표과 같이 두 가지로 나눌 수 있다.

서브쿼리는 메인쿼리 안에 포하된 종속적인 관계이기 때무넹 논리적인 실행순서는 항상 메인쿼리에서 읽혀진 데이터에 대해 서브쿼리에서 해당 조건이 만족한지를 확인하는 방식으로 수행되어야 한다. 그러나 실제 서브쿼리의 실행순서는 상황에 따라 달라질 수 있다.
반환되는 데이터의 형태에 따라 서브쿼리는 다음과 같이 세가지로 분류된다.

1. 단일 행 서브쿼리
서브쿼리가 단일 행 비교 연산자(=, <, <=, >, >=, <>) 와 함께 사용할 때는 서브쿼리의 결과 건수가 반드시 1건 이하이어야 한다. 만약, 서브쿼리의 결과 건수가 2건 이상을 반환하면 SQL 문은 실행시간 오류가 발생한다. 이런 종류의 오류는 컴파일 할 때는 알 수 없는 오류이다.
2. 다중행 서브쿼리
서브쿼리의 결과가 2건 이상 반환될 수 있다면 반드시 다중 행 비교 연산자(IN, ALL, ANY, SOME)와 함께 사용해야 한다. 그렇지 않으면 SQL문은 오류를 반환한다.
- IN (서브쿼리) : 서브쿼리의 결과에 존재하는 임의의 값과 동일한 조건을 의미한다.
- 비료연산자 ALL(서브쿼리) : 서브쿼리의 결과에 존재하는 모든 값을 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 모든 결과 값을 만족해야 하므로, 서브쿼리결과의 최대값보다 큰 모든 건이 조건을 만족한다.
- 비교연산자 ANY(서브쿼리) : 서브 쿼리의 결과에 존재하는 어느 하나의 값이라도 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 값들중 어떤 값이라도 만족하면 되므로, 서브쿼리의 결과의 최소값보다 큰 모든 건이 조건을 만족한다.
- EXISTS (서브쿼리) : 서브쿼리의 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건을 의미한다. 조건을 만족하는 건이 여러건이더라도 1건만 찾으면 더 이상 검색하지 않는다.
3. 다중 칼럼 서브쿼리
다중칼럼 서브쿼리는 서브쿼리의 결과로 여러개의 칼럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미.
4. 연관 서브쿼리
연관 서브쿼리는 서브쿼리 내에 메인쿼리 칼럼이 사용된 서브쿼리이다.
5. 그 밖의 위치에서 사용하는 서브쿼리
가. SELECT절에 사용(스칼라 서브쿼리). 스칼라 서브쿼리는 한행, 한 칼럼만을 반환하는 서브쿼리를 말한다. 스칼라 서브쿼리는 칼럼을 쓸 수 있는 대부분의 곳에서 사용할 수 있다.
나. FROM절에서 서브쿼리 사용하기(인라인 뷰)
FROM 절에는 테이블 명이 오도록 되어있다. 그런데 서브쿼리가 FROM 절에 사용되면 어떻게 될까? 서브쿼리의 결과가 마치 실행시에 동적으로 생성된 테이블인것 처럼 사용할 수 있
다. 인라인 뷰는 SQL 문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다. 그래서 일반적인 뷰를 정적뷰 라고 하고 인라인 뷰를 동적뷰 라고도 한다. 인라인뷰는 테이블 명이 올 수 있는 곳에서 사용할 수 있다. 서브쿼리의 칼럼은 메인쿼리에서 사용할 수 없다고 했다. 그러나 인라인 뷰는 동적으로 생성된 테이블이다. 인라인 뷰를 사용하는 것은 조인 방식을 사용하는 것과 같다. 그렇기 때문에 인라인 뷰의 칼럼은 SQL 문을 자유롭게 참조할 수 있다.
다. HAVING 절에서 서브쿼리 사용
HAVING절은 그룹함수와 함께 사용될 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해서 사용한다.
라. UPDATE문의 SET절에서 사용
마. INSERT문의 VALUES절에서 사용
6. VIEW
테이블은 실제로 데이터를 가지고 있는 반면, 뷰는 실제 데이터를 가지고 있지 않다. 뷰는 단지 뷰정의(VIEW DEFINITION)만을 가지고 있다. 질의에서 뷰가 사용되면 뷰 정의를 참조해서 DBMS 내부적으로 질의를 재작성 하여 질의를 수행한다. 뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블 이라고도 한다.
뷰 사용의 장점

뷰는 다음과 같이 create view문을 통해서 생성할 수 있다.
두개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법중에 또 다른 방법이 있는데 그 방법이 바로 집합연산자를 사용하는 방법이다. 조인에서는 FROM절에 검색하고자 하는 테이블을 나열하고, WHERE 절에 조인 조건을 기술하여 원하는 데이터를 조회할 수 있었다. 하지만 집합 연산자는 여러 개의 질의의 결과를 연결하여 하나로 결합하는 방식을 사용한다. 즉 집합연산자는 2개 이상의 질의 결과를 하나의 결과로 만들어 준다.
집합연산자를 사용하기 위해서는 다음 제약조건을 만족해야 한다. SELECT 절의 칼럼수가 동일하고 SELECT 절의 동일 위치에 존재하는 칼럼의 데이터 타입이 상호 호환가능해야 한다. 그렇지 않으면 데이터베이스가 오류를 반환.
집합 연산자의 종류
- UNION : 여러 개의 SQL 문의 결과에 대한 합집합으로 결과에서 모든 중복된 행은 하나의 행으로 만든다.
- UNION ALL : 여러 개의 SQL 문의 결과에 대한 합집합으로 중복된 행도 그대로 결과로 표시된다. 즉, 단순히 결과만 합쳐놓은 것이다. 일반적으로 여러 질의 결과가 상호 배타적인 일때 많이 사용한다. 개별 SQL 문의 결과가 서로 중복되지 않는 경우, UNION과 결과가 동일 하다.
- INTERSECT : 여러 개의 SQL 문의 결과에 대한 교집합이다. 중복된 행은 하나의 행으로 만든다.
- EXCEPT : 앞의 SQL 문의 결과에서 뒤의 SQL 문의 결과에 대한 차집합이다. 중복된 행은 하나의 행으로 만든다.
집합연산자는 개별 SQL문의 결과 집합에 대해 합집합, 교집합, 차집합으로 집합간의 관계를 가지고 작업을 한다.
집합 연산자를 사용하여 만들어지는 SQL문의 형태는 다음과 같다.
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명1
[WHERE 조건식 ]
[[GROUP BY 칼럼(Column)이나 표현식
[HAVING 그룹조건식 ] ]
집합 연산자
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명2
[WHERE 조건식 ]
[[GROUP BY 칼럼(Column)이나 표현식
[HAVING 그룹조건식 ] ]
[ORDER BY 1, 2 [ASC또는 DESC ] ;
----------------------------------------------------------
SELECT PLAYER_NAME 선수명, BACK_NO 백넘버
FROM PLAYER
WHERE TEAM_ID = 'K02'
UNION
SELECT PLAYER_NAME 선수명, BACK_NO 백넘버
FROM PLAYER
WHERE TEAM_ID = 'K07' ORDER BY 1;
|
집합연산자는 사용상의 제약조건을 만족한다면 어떤 형태의 SELECT문이라도 이용할 수 있다. 집합연산자는 여러개의 SELECT 문을 연결하는 것에 지나지 않는다. ORDER BY는 집합 연산을 적용한 최종결과에 대한 정렬처리이므로 가장 마지막 줄에 한번만 기술한다.
3절 계층형 질의와 셀프 조인
1. 계층형 질의
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의(HIREARCHICAL QUERY)를 사용한다. 계층형 데이터란 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터를 말한다. 예를 들어, 사원 테이블에서는 사원들 사이에 상위 사원(관리자)과 하위 사원 관계가 존재하고 조직 테이블에서는 조직들 사이에 상위 조직과 하위 조직 관계가 존재한다. 엔터티를 순환관계 데이터 모델로 설계할 경우 계층형 데이터가 발생한다. 순환관계 데이터 모델의 예로는 조직, 사원, 메뉴 등이 있다.
위 그림은 사원에 대한 순환관계 데이터 모델을 표현한 것이다. (2)계층형 구조에서 A의 하위 사원은 B, C이고 B 밑에는 사위 사원이 없고 C의 하위 사원은 D, E가 있다. 계층형 구조를 데이터로 표현한 것이 (3) 샘플 데이터 이다.
오라클은 계층형 질의를 지원하기 위해서 다름과 같은 계층형 질의 구문을 제공한다.
SELECT ...
FROM 테이블
WHERE condition AND condition...
START WITH condition
CONNECT BY [NOCYCLE] condition AND condition...
[ORDER SIBLINGS BY column, column, ...]
- START WITH 절은 계층 구조 전개의 시작 위치를 지정하는 구문이다. 즉 루트 데이터를 지정한다.
- CONNECT BY 절은 다음에 전개될 자식 데이터를 지정하는 구문이다. 자식 데이터는 CONNECT BY 절에 주어진 조건을 만족해야 한다.(조인)
-PRIOR : CONNECT BY 절에 사용되며, 현재 읽은 칼럼을 지정한다. PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 부모 데이터에서 자식데이터 (부모 -> 자식) 방향으로 전개하는 순방향 전개를 한다. 그리고 PRIOR 부모 = 자식 형태를 사용하면 반대로 자식 데이터에서 부모데이터 (자식 -> 부모) 방향으로 전개하는 역방향 전개를 한다.
- NOCYCLE : 데이터를 전개하면서 이미 나타났던 동일한 데이터가 전개 중에 다시 나타난다면 이것을 가리켜 사이틀이 형성되었다라고 말한다. 사이클이 발생한 데이터는 런타임 오류가 발생한다. 그렇지만 NOCYCLE를 추가하면 사이클이 발생한 이후의 데이터는 전개하지 않는다.
- ORDER SIBLINGS BY : 형제 노드(동일 LEVEL) 사이에서 절렬을 수행한다.
- WHERE : 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출한다. (필터링)
ORACLE 은 계층형 질의를 사용할 때 다음과 같은 가상칼럼(PSUDO COLUMN)을 제공한다.
2. 셀프조인
셀프조인이란 동일 테이블 사이의 조인을 말한다. 따라서 FROM절에 동일 테이블이 두 번 이상 나타난다. 동일 테이블 사이의 조이능ㄹ 수행하면 테이블과 칼럼 이름이 모두 동일하기 때문에 식별을 위해 반드시 테이블 별칭을 사용해야 한다. 그리고 칼럼에도 모두 테이블 별칭을 사용해서 어느 테이블의 칼럼인지 식별해줘야 한다. 이외 사항은 조인과 동일하다.
셀프 조인에 대한 기본적인 사용법은 다음과 같다.
SELECT ALIAS명1.칼럼명, ALIAS명2.칼럼명, ...
FROM 테이블1 ALIAS명1, 테이블2 ALIAS명2
WHERE ALIAS명1.칼럼명2 = ALIAS명2.칼럼명1;
|
SELECT WORKER.ID 사원번호, WORKER.NAME 사원명, MANAGER.NAME 관리자명
FROM EMP WORKER, EMP MANAGER
WHERE WORKER.MGR = MANAGER.ID;
|
계층형 질의에서 살펴보았던 사원이라는 테이블 속에는 사원과 관리자가 모두 하나의 사원이라는 개념으로 동일시하여 같이 입력되어 있다. 이것을 이용해서 다음 문제를 셀프 조인으로 해결해 보면 다음과 같다. "자신과 상위, 차상위 관리자를 같은 줄에 표시하라." 이 문제를 해결하기 위해서는 FROM 절에 사원 테이블을 두 번 사용해야 한다.
셀프 조인은 동일한 테이블 이지만 위 그림과 같이 개념적으로는 두 개의 서로 다른 테이블을 사용하는 것과 동일하다. 동일 테이블을 다른 테이블인 것처럼 처리하기 위해 테이블 별칭을 사용한다. 여기서는 E1, E2 테이블 별칭을 사용하였다. 차상위 관리자를 구하기 위해서 E1.관리자 = E2.사원 조건을 사용한다.
4절 서브쿼리
서브쿼리란 하나의 sql문 안에 포함되어 있는 또 다른 sql문을 말하낟. 서브쿼리는 알려지지 않은 기준을 이용한 검색을 위해 사용하낟. 서브쿼리는 다음그림과 같이 메인 쿼리가 서브 쿼리를 포함하는 종속적인 관계이다.
조인은 조인에 참여하는 모든 테이블이 대등한 관계에 있기 때문에 조인에 참여하는 모든 테이블의 칼럼을 어느 위치에서라도 자유롭게 사용할 수 있다. 그러나 서브쿼리는 메인쿼리의 칼럼을 모두 사용할 수 있지만 메인쿼리는 서브쿼리의 칼럼을 사용할 수 없다. 질의 결과에 서브쿼리 칼럼을 표시해야 한다면 조인 방식으로 변환하거나 함수, 스칼라 서브쿼리 등을 사용해야 한다.
조인은 집합간의 곱의 관계이다. 즉, 1:1 관계의 테이블이 조인하면 1(=1*1)레벨의 집합이 생성되고, 1:M 관계의 테이블을 조인하면 M(=1*M)레벨의 집합이 생성된다. 그리고 M:N 관계의 테이블을 조인하면 MN(=M*N) 레벨의 집합이 결과로서 생성된다. 예를 들어 조직(1)과 사원(M) 테이블을 조인하면 결과는 사원레벨(M)의 집합이 생성된다. 그러나 서브쿼리는 서브쿼리 레벨과는 상관없이 항상 메인쿼리 레벨로 결과 집합이 생성된다. 예를 들어, 메인쿼리로 조직(1), 서브쿼리로 사원(M) 테이블을 사용하면 결과집합은 조직(1) 레벨이 된다.
SQL 문에서 서브쿼리 방식을 사용해야 할 때 잘못 판단하여 조인 방식을 사용하는 경우가 있다. 예를들어, 결과는 조직 레벨이고 사원테이블에서 체크해야 할 조건이 존재한다고 가정하다. 이런 상황에서 SQL 문을 작성할 때 조인을 사용한다면 결과 집합은 사원(M) 레벨이 될 것이다. 이렇게 되면 원하는 결과가 아니기 때문에 SQL 문에 DISTINCT를 추가해서 결과를 다시 조직(1) 레벨로 만든다. 이와같은 상황에서는 조인 방식이 아니라 서브쿼리 방식을 사용해야 한다. 메인쿼리로 조직을 사용하고 서브쿼리로 사원 테이블을 사용하면 결과 집합은 조직레벨이 되기 때문에 원하는 결과가 된다.
서브쿼리를 사용할 때 다음 사항에 주의해야 한다.
1. 서브쿼리를 괄호로 감싸서 사용한다.
2. 서브쿼리는 단일행 또는 복수행 비교 연산자와 함께 사용 가능하다. 단일행 비교 연산자는 서브쿼리의 결과가 반드시 1건 이하이어야 하고 복수 행 비교 연산자는 서브쿼리의 결과 건수와 상관없다.
3. 서브쿼리에서는 ORDER BY를 사용하지 못한다. ORDER BY 적은 SELECT절에서 오직 한 개만 올 수 있기 때문에 ORDER BY절은 메인 쿼리의 마지막 문장에 위치해야 한다.
서브쿼리가 SQL 문에서 사용이 가능한 곳은 다음과 같다.
- SELECT 절
- FROM 절
- WHERE 절
- HAVING 절
- ORDER BY 절
- INSERT문의 VALUES 절
- UPDATE 문의 SET 절
서브쿼리의 종류는 동작하는 방식이나 반환되는 데이터의 형태에 따라 분류할 수 있다. 동작하는 방식에 따라 서브쿼리를 분류하면 다음표과 같이 두 가지로 나눌 수 있다.
서브쿼리는 메인쿼리 안에 포하된 종속적인 관계이기 때무넹 논리적인 실행순서는 항상 메인쿼리에서 읽혀진 데이터에 대해 서브쿼리에서 해당 조건이 만족한지를 확인하는 방식으로 수행되어야 한다. 그러나 실제 서브쿼리의 실행순서는 상황에 따라 달라질 수 있다.
반환되는 데이터의 형태에 따라 서브쿼리는 다음과 같이 세가지로 분류된다.
1. 단일 행 서브쿼리
서브쿼리가 단일 행 비교 연산자(=, <, <=, >, >=, <>) 와 함께 사용할 때는 서브쿼리의 결과 건수가 반드시 1건 이하이어야 한다. 만약, 서브쿼리의 결과 건수가 2건 이상을 반환하면 SQL 문은 실행시간 오류가 발생한다. 이런 종류의 오류는 컴파일 할 때는 알 수 없는 오류이다.
2. 다중행 서브쿼리
서브쿼리의 결과가 2건 이상 반환될 수 있다면 반드시 다중 행 비교 연산자(IN, ALL, ANY, SOME)와 함께 사용해야 한다. 그렇지 않으면 SQL문은 오류를 반환한다.
- IN (서브쿼리) : 서브쿼리의 결과에 존재하는 임의의 값과 동일한 조건을 의미한다.
- 비료연산자 ALL(서브쿼리) : 서브쿼리의 결과에 존재하는 모든 값을 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 모든 결과 값을 만족해야 하므로, 서브쿼리결과의 최대값보다 큰 모든 건이 조건을 만족한다.
- 비교연산자 ANY(서브쿼리) : 서브 쿼리의 결과에 존재하는 어느 하나의 값이라도 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 값들중 어떤 값이라도 만족하면 되므로, 서브쿼리의 결과의 최소값보다 큰 모든 건이 조건을 만족한다.
- EXISTS (서브쿼리) : 서브쿼리의 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건을 의미한다. 조건을 만족하는 건이 여러건이더라도 1건만 찾으면 더 이상 검색하지 않는다.
3. 다중 칼럼 서브쿼리
다중칼럼 서브쿼리는 서브쿼리의 결과로 여러개의 칼럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미.
4. 연관 서브쿼리
연관 서브쿼리는 서브쿼리 내에 메인쿼리 칼럼이 사용된 서브쿼리이다.
5. 그 밖의 위치에서 사용하는 서브쿼리
가. SELECT절에 사용(스칼라 서브쿼리). 스칼라 서브쿼리는 한행, 한 칼럼만을 반환하는 서브쿼리를 말한다. 스칼라 서브쿼리는 칼럼을 쓸 수 있는 대부분의 곳에서 사용할 수 있다.
나. FROM절에서 서브쿼리 사용하기(인라인 뷰)
FROM 절에는 테이블 명이 오도록 되어있다. 그런데 서브쿼리가 FROM 절에 사용되면 어떻게 될까? 서브쿼리의 결과가 마치 실행시에 동적으로 생성된 테이블인것 처럼 사용할 수 있
다. 인라인 뷰는 SQL 문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다. 그래서 일반적인 뷰를 정적뷰 라고 하고 인라인 뷰를 동적뷰 라고도 한다. 인라인뷰는 테이블 명이 올 수 있는 곳에서 사용할 수 있다. 서브쿼리의 칼럼은 메인쿼리에서 사용할 수 없다고 했다. 그러나 인라인 뷰는 동적으로 생성된 테이블이다. 인라인 뷰를 사용하는 것은 조인 방식을 사용하는 것과 같다. 그렇기 때문에 인라인 뷰의 칼럼은 SQL 문을 자유롭게 참조할 수 있다.
다. HAVING 절에서 서브쿼리 사용
HAVING절은 그룹함수와 함께 사용될 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해서 사용한다.
라. UPDATE문의 SET절에서 사용
마. INSERT문의 VALUES절에서 사용
6. VIEW
테이블은 실제로 데이터를 가지고 있는 반면, 뷰는 실제 데이터를 가지고 있지 않다. 뷰는 단지 뷰정의(VIEW DEFINITION)만을 가지고 있다. 질의에서 뷰가 사용되면 뷰 정의를 참조해서 DBMS 내부적으로 질의를 재작성 하여 질의를 수행한다. 뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블 이라고도 한다.
뷰 사용의 장점
뷰는 다음과 같이 create view문을 통해서 생성할 수 있다.
CREATE VIEW V_PLAYER_TEAM
AS SELECT P.PLAYER_NAME, P.POSITION, P.BACK_NO, P.TEAM_ID, T.TEAM_NAME
FROM PLAYER P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID;
|
피드 구독하기:
글 (Atom)