두개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법중에 또 다른 방법이 있는데 그 방법이 바로 집합연산자를 사용하는 방법이다. 조인에서는 FROM절에 검색하고자 하는 테이블을 나열하고, WHERE 절에 조인 조건을 기술하여 원하는 데이터를 조회할 수 있었다. 하지만 집합 연산자는 여러 개의 질의의 결과를 연결하여 하나로 결합하는 방식을 사용한다. 즉 집합연산자는 2개 이상의 질의 결과를 하나의 결과로 만들어 준다.
집합연산자를 사용하기 위해서는 다음 제약조건을 만족해야 한다. SELECT 절의 칼럼수가 동일하고 SELECT 절의 동일 위치에 존재하는 칼럼의 데이터 타입이 상호 호환가능해야 한다. 그렇지 않으면 데이터베이스가 오류를 반환.
집합 연산자의 종류
- UNION : 여러 개의 SQL 문의 결과에 대한 합집합으로 결과에서 모든 중복된 행은 하나의 행으로 만든다.
- UNION ALL : 여러 개의 SQL 문의 결과에 대한 합집합으로 중복된 행도 그대로 결과로 표시된다. 즉, 단순히 결과만 합쳐놓은 것이다. 일반적으로 여러 질의 결과가 상호 배타적인 일때 많이 사용한다. 개별 SQL 문의 결과가 서로 중복되지 않는 경우, UNION과 결과가 동일 하다.
- INTERSECT : 여러 개의 SQL 문의 결과에 대한 교집합이다. 중복된 행은 하나의 행으로 만든다.
- EXCEPT : 앞의 SQL 문의 결과에서 뒤의 SQL 문의 결과에 대한 차집합이다. 중복된 행은 하나의 행으로 만든다.
집합연산자는 개별 SQL문의 결과 집합에 대해 합집합, 교집합, 차집합으로 집합간의 관계를 가지고 작업을 한다.

집합 연산자를 사용하여 만들어지는 SQL문의 형태는 다음과 같다.
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명1
[WHERE 조건식 ]
[[GROUP BY 칼럼(Column)이나 표현식
[HAVING 그룹조건식 ] ]
집합 연산자
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명2
[WHERE 조건식 ]
[[GROUP BY 칼럼(Column)이나 표현식
[HAVING 그룹조건식 ] ]
[ORDER BY 1, 2 [ASC또는 DESC ] ;
----------------------------------------------------------
SELECT PLAYER_NAME 선수명, BACK_NO 백넘버
FROM PLAYER
WHERE TEAM_ID = 'K02'
UNION
SELECT PLAYER_NAME 선수명, BACK_NO 백넘버
FROM PLAYER
WHERE TEAM_ID = 'K07' ORDER BY 1;
|
집합연산자는 사용상의 제약조건을 만족한다면 어떤 형태의 SELECT문이라도 이용할 수 있다. 집합연산자는 여러개의 SELECT 문을 연결하는 것에 지나지 않는다. ORDER BY는 집합 연산을 적용한 최종결과에 대한 정렬처리이므로 가장 마지막 줄에 한번만 기술한다.
3절 계층형 질의와 셀프 조인
1. 계층형 질의
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의(HIREARCHICAL QUERY)를 사용한다. 계층형 데이터란 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터를 말한다. 예를 들어, 사원 테이블에서는 사원들 사이에 상위 사원(관리자)과 하위 사원 관계가 존재하고 조직 테이블에서는 조직들 사이에 상위 조직과 하위 조직 관계가 존재한다. 엔터티를 순환관계 데이터 모델로 설계할 경우 계층형 데이터가 발생한다. 순환관계 데이터 모델의 예로는 조직, 사원, 메뉴 등이 있다.

위 그림은 사원에 대한 순환관계 데이터 모델을 표현한 것이다. (2)계층형 구조에서 A의 하위 사원은 B, C이고 B 밑에는 사위 사원이 없고 C의 하위 사원은 D, E가 있다. 계층형 구조를 데이터로 표현한 것이 (3) 샘플 데이터 이다.
오라클은 계층형 질의를 지원하기 위해서 다름과 같은 계층형 질의 구문을 제공한다.
SELECT ...
FROM 테이블
WHERE condition AND condition...
START WITH condition
CONNECT BY [NOCYCLE] condition AND condition...
[ORDER SIBLINGS BY column, column, ...]
- START WITH 절은 계층 구조 전개의 시작 위치를 지정하는 구문이다. 즉 루트 데이터를 지정한다.
- CONNECT BY 절은 다음에 전개될 자식 데이터를 지정하는 구문이다. 자식 데이터는 CONNECT BY 절에 주어진 조건을 만족해야 한다.(조인)
-PRIOR : CONNECT BY 절에 사용되며, 현재 읽은 칼럼을 지정한다. PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 부모 데이터에서 자식데이터 (부모 -> 자식) 방향으로 전개하는 순방향 전개를 한다. 그리고 PRIOR 부모 = 자식 형태를 사용하면 반대로 자식 데이터에서 부모데이터 (자식 -> 부모) 방향으로 전개하는 역방향 전개를 한다.
- NOCYCLE : 데이터를 전개하면서 이미 나타났던 동일한 데이터가 전개 중에 다시 나타난다면 이것을 가리켜 사이틀이 형성되었다라고 말한다. 사이클이 발생한 데이터는 런타임 오류가 발생한다. 그렇지만 NOCYCLE를 추가하면 사이클이 발생한 이후의 데이터는 전개하지 않는다.
- ORDER SIBLINGS BY : 형제 노드(동일 LEVEL) 사이에서 절렬을 수행한다.
- WHERE : 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출한다. (필터링)
ORACLE 은 계층형 질의를 사용할 때 다음과 같은 가상칼럼(PSUDO COLUMN)을 제공한다.

2. 셀프조인
셀프조인이란 동일 테이블 사이의 조인을 말한다. 따라서 FROM절에 동일 테이블이 두 번 이상 나타난다. 동일 테이블 사이의 조이능ㄹ 수행하면 테이블과 칼럼 이름이 모두 동일하기 때문에 식별을 위해 반드시 테이블 별칭을 사용해야 한다. 그리고 칼럼에도 모두 테이블 별칭을 사용해서 어느 테이블의 칼럼인지 식별해줘야 한다. 이외 사항은 조인과 동일하다.
셀프 조인에 대한 기본적인 사용법은 다음과 같다.
SELECT ALIAS명1.칼럼명, ALIAS명2.칼럼명, ...
FROM 테이블1 ALIAS명1, 테이블2 ALIAS명2
WHERE ALIAS명1.칼럼명2 = ALIAS명2.칼럼명1;
|
SELECT WORKER.ID 사원번호, WORKER.NAME 사원명, MANAGER.NAME 관리자명
FROM EMP WORKER, EMP MANAGER
WHERE WORKER.MGR = MANAGER.ID;
|
계층형 질의에서 살펴보았던 사원이라는 테이블 속에는 사원과 관리자가 모두 하나의 사원이라는 개념으로 동일시하여 같이 입력되어 있다. 이것을 이용해서 다음 문제를 셀프 조인으로 해결해 보면 다음과 같다. "자신과 상위, 차상위 관리자를 같은 줄에 표시하라." 이 문제를 해결하기 위해서는 FROM 절에 사원 테이블을 두 번 사용해야 한다.

셀프 조인은 동일한 테이블 이지만 위 그림과 같이 개념적으로는 두 개의 서로 다른 테이블을 사용하는 것과 동일하다. 동일 테이블을 다른 테이블인 것처럼 처리하기 위해 테이블 별칭을 사용한다. 여기서는 E1, E2 테이블 별칭을 사용하였다. 차상위 관리자를 구하기 위해서 E1.관리자 = E2.사원 조건을 사용한다.
4절 서브쿼리
서브쿼리란 하나의 sql문 안에 포함되어 있는 또 다른 sql문을 말하낟. 서브쿼리는 알려지지 않은 기준을 이용한 검색을 위해 사용하낟. 서브쿼리는 다음그림과 같이 메인 쿼리가 서브 쿼리를 포함하는 종속적인 관계이다.
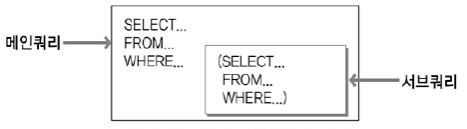
조인은 조인에 참여하는 모든 테이블이 대등한 관계에 있기 때문에 조인에 참여하는 모든 테이블의 칼럼을 어느 위치에서라도 자유롭게 사용할 수 있다. 그러나 서브쿼리는 메인쿼리의 칼럼을 모두 사용할 수 있지만 메인쿼리는 서브쿼리의 칼럼을 사용할 수 없다. 질의 결과에 서브쿼리 칼럼을 표시해야 한다면 조인 방식으로 변환하거나 함수, 스칼라 서브쿼리 등을 사용해야 한다.
조인은 집합간의 곱의 관계이다. 즉, 1:1 관계의 테이블이 조인하면 1(=1*1)레벨의 집합이 생성되고, 1:M 관계의 테이블을 조인하면 M(=1*M)레벨의 집합이 생성된다. 그리고 M:N 관계의 테이블을 조인하면 MN(=M*N) 레벨의 집합이 결과로서 생성된다. 예를 들어 조직(1)과 사원(M) 테이블을 조인하면 결과는 사원레벨(M)의 집합이 생성된다. 그러나 서브쿼리는 서브쿼리 레벨과는 상관없이 항상 메인쿼리 레벨로 결과 집합이 생성된다. 예를 들어, 메인쿼리로 조직(1), 서브쿼리로 사원(M) 테이블을 사용하면 결과집합은 조직(1) 레벨이 된다.
SQL 문에서 서브쿼리 방식을 사용해야 할 때 잘못 판단하여 조인 방식을 사용하는 경우가 있다. 예를들어, 결과는 조직 레벨이고 사원테이블에서 체크해야 할 조건이 존재한다고 가정하다. 이런 상황에서 SQL 문을 작성할 때 조인을 사용한다면 결과 집합은 사원(M) 레벨이 될 것이다. 이렇게 되면 원하는 결과가 아니기 때문에 SQL 문에 DISTINCT를 추가해서 결과를 다시 조직(1) 레벨로 만든다. 이와같은 상황에서는 조인 방식이 아니라 서브쿼리 방식을 사용해야 한다. 메인쿼리로 조직을 사용하고 서브쿼리로 사원 테이블을 사용하면 결과 집합은 조직레벨이 되기 때문에 원하는 결과가 된다.
서브쿼리를 사용할 때 다음 사항에 주의해야 한다.
1. 서브쿼리를 괄호로 감싸서 사용한다.
2. 서브쿼리는 단일행 또는 복수행 비교 연산자와 함께 사용 가능하다. 단일행 비교 연산자는 서브쿼리의 결과가 반드시 1건 이하이어야 하고 복수 행 비교 연산자는 서브쿼리의 결과 건수와 상관없다.
3. 서브쿼리에서는 ORDER BY를 사용하지 못한다. ORDER BY 적은 SELECT절에서 오직 한 개만 올 수 있기 때문에 ORDER BY절은 메인 쿼리의 마지막 문장에 위치해야 한다.
서브쿼리가 SQL 문에서 사용이 가능한 곳은 다음과 같다.
- SELECT 절
- FROM 절
- WHERE 절
- HAVING 절
- ORDER BY 절
- INSERT문의 VALUES 절
- UPDATE 문의 SET 절
서브쿼리의 종류는 동작하는 방식이나 반환되는 데이터의 형태에 따라 분류할 수 있다. 동작하는 방식에 따라 서브쿼리를 분류하면 다음표과 같이 두 가지로 나눌 수 있다.

서브쿼리는 메인쿼리 안에 포하된 종속적인 관계이기 때무넹 논리적인 실행순서는 항상 메인쿼리에서 읽혀진 데이터에 대해 서브쿼리에서 해당 조건이 만족한지를 확인하는 방식으로 수행되어야 한다. 그러나 실제 서브쿼리의 실행순서는 상황에 따라 달라질 수 있다.
반환되는 데이터의 형태에 따라 서브쿼리는 다음과 같이 세가지로 분류된다.

1. 단일 행 서브쿼리
서브쿼리가 단일 행 비교 연산자(=, <, <=, >, >=, <>) 와 함께 사용할 때는 서브쿼리의 결과 건수가 반드시 1건 이하이어야 한다. 만약, 서브쿼리의 결과 건수가 2건 이상을 반환하면 SQL 문은 실행시간 오류가 발생한다. 이런 종류의 오류는 컴파일 할 때는 알 수 없는 오류이다.
2. 다중행 서브쿼리
서브쿼리의 결과가 2건 이상 반환될 수 있다면 반드시 다중 행 비교 연산자(IN, ALL, ANY, SOME)와 함께 사용해야 한다. 그렇지 않으면 SQL문은 오류를 반환한다.
- IN (서브쿼리) : 서브쿼리의 결과에 존재하는 임의의 값과 동일한 조건을 의미한다.
- 비료연산자 ALL(서브쿼리) : 서브쿼리의 결과에 존재하는 모든 값을 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 모든 결과 값을 만족해야 하므로, 서브쿼리결과의 최대값보다 큰 모든 건이 조건을 만족한다.
- 비교연산자 ANY(서브쿼리) : 서브 쿼리의 결과에 존재하는 어느 하나의 값이라도 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 값들중 어떤 값이라도 만족하면 되므로, 서브쿼리의 결과의 최소값보다 큰 모든 건이 조건을 만족한다.
- EXISTS (서브쿼리) : 서브쿼리의 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건을 의미한다. 조건을 만족하는 건이 여러건이더라도 1건만 찾으면 더 이상 검색하지 않는다.
3. 다중 칼럼 서브쿼리
다중칼럼 서브쿼리는 서브쿼리의 결과로 여러개의 칼럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미.
4. 연관 서브쿼리
연관 서브쿼리는 서브쿼리 내에 메인쿼리 칼럼이 사용된 서브쿼리이다.
5. 그 밖의 위치에서 사용하는 서브쿼리
가. SELECT절에 사용(스칼라 서브쿼리). 스칼라 서브쿼리는 한행, 한 칼럼만을 반환하는 서브쿼리를 말한다. 스칼라 서브쿼리는 칼럼을 쓸 수 있는 대부분의 곳에서 사용할 수 있다.
나. FROM절에서 서브쿼리 사용하기(인라인 뷰)
FROM 절에는 테이블 명이 오도록 되어있다. 그런데 서브쿼리가 FROM 절에 사용되면 어떻게 될까? 서브쿼리의 결과가 마치 실행시에 동적으로 생성된 테이블인것 처럼 사용할 수 있
다. 인라인 뷰는 SQL 문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다. 그래서 일반적인 뷰를 정적뷰 라고 하고 인라인 뷰를 동적뷰 라고도 한다. 인라인뷰는 테이블 명이 올 수 있는 곳에서 사용할 수 있다. 서브쿼리의 칼럼은 메인쿼리에서 사용할 수 없다고 했다. 그러나 인라인 뷰는 동적으로 생성된 테이블이다. 인라인 뷰를 사용하는 것은 조인 방식을 사용하는 것과 같다. 그렇기 때문에 인라인 뷰의 칼럼은 SQL 문을 자유롭게 참조할 수 있다.
다. HAVING 절에서 서브쿼리 사용
HAVING절은 그룹함수와 함께 사용될 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해서 사용한다.
라. UPDATE문의 SET절에서 사용
마. INSERT문의 VALUES절에서 사용
6. VIEW
테이블은 실제로 데이터를 가지고 있는 반면, 뷰는 실제 데이터를 가지고 있지 않다. 뷰는 단지 뷰정의(VIEW DEFINITION)만을 가지고 있다. 질의에서 뷰가 사용되면 뷰 정의를 참조해서 DBMS 내부적으로 질의를 재작성 하여 질의를 수행한다. 뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블 이라고도 한다.
뷰 사용의 장점

뷰는 다음과 같이 create view문을 통해서 생성할 수 있다.
CREATE VIEW V_PLAYER_TEAM
AS SELECT P.PLAYER_NAME, P.POSITION, P.BACK_NO, P.TEAM_ID, T.TEAM_NAME
FROM PLAYER P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID;
|