[출처] http://zoonoo.egloos.com/2272248
1. NESTED LOOP JOIN
NESTED LOOP JOIN이란 먼저 선행테이블(Driving Table)의 처리범위를 하나씩 액세스하면서 그 추출된 값으로 연결할 테이블을 조인하는 방식이다.
따라서 선행테이블의 결정과 처리범위에 따라 성능이 좌우된다.
HINT: /*+ use_nl (테이블) */
[특징]
- 순차적으로 처리된다. 선행테이블의 처리범위에 있는 각각의 로우들이 순차적으로 수행될 뿐만 아니라 테이블간의 연결도 순차적이다.
- 먼저 액세스되는 테이블(Driving Table)의 처리범위에 의해 처리량이 결정된다
- 나중에 처리되는 테이블은 앞서 처리된 값을 받아 액세스된다. 즉, 자신에게 주어진 상수값에 의해 스스로 범위를 줄이는 것이 아니라 값을 받아서 처리범위가 정해진다.
- 주어진 조건에 있는 모든 컬럼들이 인덱스를 가지고 있더라도 모두가 사용되는 것은 아니다. 연결되는 방향에 따라 사용되는 인덱스들이 전혀 달라질 수 있다.
- 연결고리의 인덱스 유무에 따라 액세스 방향 및 수행속도에 많은 차이가 발생된다.
[사용기준]
- 부분범위처리를 하는 경우에 주로 유리해진다.
- 조인되는 어느 한쪽이 상대방 테이블에서 추출된 결과를 받아야 처리범위를 줄일 수 있는 상태라면 항상 유리해진다.
- 주로 처리량이 적은 경우(많더라도 부분범위처리가 가능한 경우)에 유리해진다. 그것은 처리방식이 주로 랜덤 액세스방식이므로 많은 양의 랜덤 액세스가 발생한다면 수행속도가 당연히 나빠지기 때문이다.
- 순차적으로 처리되기 때문에 어떤 테이블이 먼저 액세스되느냐에 따라 수행속도에 많은 영향을 미치므로 최적의 액세스 순서가 되도록 적절한 조치가 요구된다.
- 선행테이블의 처리 범위가 많거나 연결 테이블의 랜덤 액세스의 양이 아주 많다면 SORT MERGE JOIN보다 불리해지는 경우가 많다.
- 일반적으로 온라인 어플리케이션에 유리하다.
2. SORT MERGE JOIN
SORT MERGE JOIN이란 양쪽 테이블의 처리범위를 각자 액세스하여 정렬한 결과를 차례로 스캔하면서 연결고리의 조건으로 머지해 가는 방식을 말한다. 이 방식은 경우에 따라 Nested Loop Join보다 훨씬 빨라지는 경우도 많이 있으며 랜덤 액세스가 줄어들어 시스템의 부하를 감소시키지만 일반적으로 NESTED LOOP JOIN 보다는 사용되는 빈도가 적은 편이다.
이 방식의 가장 큰 특징은 상대방에게 아무런 값도 받지 않고 자신이 가지고 있는 조건만으로 처리범위가 정해지며, 랜덤 액세스를 줄일 수는 있으나 항상 전체범위처리를 한다는 것이다.
HINT: /*+ use_merge(테이블) */
[특징]
- 동시적으로 처리된다. 테이블 각자가 자신의 처리범위를 액세스하여 정렬해 둔다.
- 결코 부분범위처리를 할 수가 없으며, 항상 전체범위처리를 한다.
- 주로 스캔방식으로 처리된다. 자신의 처리범위를 줄이기 위해 인덱스를 사용하는 경우만 랜덤 액세스이고 머지작업은 스캔방식이다.
- 주어진 조건에 있는 모든 컬럼들이 인덱스를 가지고 있더라도 모두가 사용되는 것은 아니다. 연결고리가 되는 컬럼은 인덱스를 전혀 사용하지 않는다.
- 조인의 방향과는 전혀 무관하다.
- 스스로 자신의 처리범위를 줄이기 위해 사용되는 인덱스는 대개 가장 유리한 한가지만 사용되어진다. 그러나 그 외의 조건들은 비록 인덱스를 사용하지 못하더라도 작업대상을 줄여 주기 때문에 중요한 의미를 가진다.
[사용기준]
- 전체범위처리를 하는 경우에 주로 유리해진다.
- 상대방 테이블에서 어떤 상수값을 받지 않고도 처리범위를 줄일 수 있는 상태인 경우 주로 유리해 질 수 있다. 상수값을 받아 처리(NESTED LOOP JOIN)한 범위의 크기와 처리범위를 줄여 처리(SORT MERGE JOIN)한 범위의 크기를 대비해보아 상수값을 받아 줄여진 범위가 약 30% 이상이라면 SORT MERGE JOIN이 일반적으로 유리해진다. 그러나 부분범위처리가 되는 경우라면 전혀 달라질 수 있다. 이런 경우는 처리할 전체범위를 비교하지 말고 첫번째 운반단위에 도달하기 위해 액세스하는 범위애 대해서 판단해야 한다.
- 주로 처리량이 많은 경우 (항상 전체범위처리를 해야 하는 경우)에 유리해진다. 그것은 처리방식이 주로 스캔방식이므로 많은 양의 랜덤 액세스를 줄일 수가 있기 때문이다.
- 스스로 자신의 처리범위를 어떻게 줄일 수 있느냐가 수행속도에 많은 영향을 미치므로 보다 효율적으로 액세스할 수 잇는 인덱스 구성이 중요한다.
- 처리할 데이터량이 적은 온라인 애플리케이션에서는 NESTED LOOP JOIN이 유리한 경우가 많으므로 함부로 SORT MERGE JOIN을 사용하지 말아야 한다.
- 일반적으로 배치작업시 유리하다.
3. HASH JOIN
해시값을이용하여 테이블을 조인하는 방식이다.
HINT: /*+ use_hash(테이블) */
- 적은테이블과 큰테이블의 조인시에 유리하다.
- Equal 조인에서만 가능하다.
- 선행테이블에 인덱스를 필요로 하지 않고 각 테이블을 한번만 읽음
- 다른조인방법보다 CPU자원을 많이 소비하며 양쪽 테이블의 스켄이 동시에 일어남.
2013년 4월 19일 금요일
2013년 3월 16일 토요일
협상의 룰, 난 어떤 사람이 되어야 하는가
큰 협상을 하려면 거침없이 한치도 두려움 없이 원하는 것을 묻고 또 물어야 한다
협상원칙 - 품질좋은 제품을 먼저 갖추고, 우리의 스토리를 한 치 오차도 없이 상대방에게 정확히 전달하며, 마지막으로 '우리 가치가 이 정도나 되니 더 돈을 받아야 되겠다' 고 부끄럼 없이 당당하게 요구하는것
다른 사람이 원하는 당신이 되면 안된다
직장에서 최고가 되려면 당신의 상사를 빛나게 하세요
- 그가 나오기 전에 출근하고 그가 퇴근하기 전까지 가지 말고 그를 어떻게 도울 수 있을까 생각하세요
협상은 꾀를 부리지 말고 단순하게
매우 강력한 의견을 가지되 자존심은 버리고 토론
실패를 포용하라
2013년 2월 26일 화요일
SQL 전문가 가이드 2장 2절~4절 집합연산자
2절 집합 연산자(SET OPERATOR)
두개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법중에 또 다른 방법이 있는데 그 방법이 바로 집합연산자를 사용하는 방법이다. 조인에서는 FROM절에 검색하고자 하는 테이블을 나열하고, WHERE 절에 조인 조건을 기술하여 원하는 데이터를 조회할 수 있었다. 하지만 집합 연산자는 여러 개의 질의의 결과를 연결하여 하나로 결합하는 방식을 사용한다. 즉 집합연산자는 2개 이상의 질의 결과를 하나의 결과로 만들어 준다.
집합연산자를 사용하기 위해서는 다음 제약조건을 만족해야 한다. SELECT 절의 칼럼수가 동일하고 SELECT 절의 동일 위치에 존재하는 칼럼의 데이터 타입이 상호 호환가능해야 한다. 그렇지 않으면 데이터베이스가 오류를 반환.
집합 연산자의 종류
- UNION : 여러 개의 SQL 문의 결과에 대한 합집합으로 결과에서 모든 중복된 행은 하나의 행으로 만든다.
- UNION ALL : 여러 개의 SQL 문의 결과에 대한 합집합으로 중복된 행도 그대로 결과로 표시된다. 즉, 단순히 결과만 합쳐놓은 것이다. 일반적으로 여러 질의 결과가 상호 배타적인 일때 많이 사용한다. 개별 SQL 문의 결과가 서로 중복되지 않는 경우, UNION과 결과가 동일 하다.
- INTERSECT : 여러 개의 SQL 문의 결과에 대한 교집합이다. 중복된 행은 하나의 행으로 만든다.
- EXCEPT : 앞의 SQL 문의 결과에서 뒤의 SQL 문의 결과에 대한 차집합이다. 중복된 행은 하나의 행으로 만든다.
집합연산자는 개별 SQL문의 결과 집합에 대해 합집합, 교집합, 차집합으로 집합간의 관계를 가지고 작업을 한다.

집합연산자는 사용상의 제약조건을 만족한다면 어떤 형태의 SELECT문이라도 이용할 수 있다. 집합연산자는 여러개의 SELECT 문을 연결하는 것에 지나지 않는다. ORDER BY는 집합 연산을 적용한 최종결과에 대한 정렬처리이므로 가장 마지막 줄에 한번만 기술한다.
3절 계층형 질의와 셀프 조인
1. 계층형 질의
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의(HIREARCHICAL QUERY)를 사용한다. 계층형 데이터란 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터를 말한다. 예를 들어, 사원 테이블에서는 사원들 사이에 상위 사원(관리자)과 하위 사원 관계가 존재하고 조직 테이블에서는 조직들 사이에 상위 조직과 하위 조직 관계가 존재한다. 엔터티를 순환관계 데이터 모델로 설계할 경우 계층형 데이터가 발생한다. 순환관계 데이터 모델의 예로는 조직, 사원, 메뉴 등이 있다.

위 그림은 사원에 대한 순환관계 데이터 모델을 표현한 것이다. (2)계층형 구조에서 A의 하위 사원은 B, C이고 B 밑에는 사위 사원이 없고 C의 하위 사원은 D, E가 있다. 계층형 구조를 데이터로 표현한 것이 (3) 샘플 데이터 이다.
오라클은 계층형 질의를 지원하기 위해서 다름과 같은 계층형 질의 구문을 제공한다.
SELECT ...
FROM 테이블
WHERE condition AND condition...
START WITH condition
CONNECT BY [NOCYCLE] condition AND condition...
[ORDER SIBLINGS BY column, column, ...]
- START WITH 절은 계층 구조 전개의 시작 위치를 지정하는 구문이다. 즉 루트 데이터를 지정한다.
- CONNECT BY 절은 다음에 전개될 자식 데이터를 지정하는 구문이다. 자식 데이터는 CONNECT BY 절에 주어진 조건을 만족해야 한다.(조인)
-PRIOR : CONNECT BY 절에 사용되며, 현재 읽은 칼럼을 지정한다. PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 부모 데이터에서 자식데이터 (부모 -> 자식) 방향으로 전개하는 순방향 전개를 한다. 그리고 PRIOR 부모 = 자식 형태를 사용하면 반대로 자식 데이터에서 부모데이터 (자식 -> 부모) 방향으로 전개하는 역방향 전개를 한다.
- NOCYCLE : 데이터를 전개하면서 이미 나타났던 동일한 데이터가 전개 중에 다시 나타난다면 이것을 가리켜 사이틀이 형성되었다라고 말한다. 사이클이 발생한 데이터는 런타임 오류가 발생한다. 그렇지만 NOCYCLE를 추가하면 사이클이 발생한 이후의 데이터는 전개하지 않는다.
- ORDER SIBLINGS BY : 형제 노드(동일 LEVEL) 사이에서 절렬을 수행한다.
- WHERE : 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출한다. (필터링)
ORACLE 은 계층형 질의를 사용할 때 다음과 같은 가상칼럼(PSUDO COLUMN)을 제공한다.

2. 셀프조인
셀프조인이란 동일 테이블 사이의 조인을 말한다. 따라서 FROM절에 동일 테이블이 두 번 이상 나타난다. 동일 테이블 사이의 조이능ㄹ 수행하면 테이블과 칼럼 이름이 모두 동일하기 때문에 식별을 위해 반드시 테이블 별칭을 사용해야 한다. 그리고 칼럼에도 모두 테이블 별칭을 사용해서 어느 테이블의 칼럼인지 식별해줘야 한다. 이외 사항은 조인과 동일하다.
셀프 조인에 대한 기본적인 사용법은 다음과 같다.
계층형 질의에서 살펴보았던 사원이라는 테이블 속에는 사원과 관리자가 모두 하나의 사원이라는 개념으로 동일시하여 같이 입력되어 있다. 이것을 이용해서 다음 문제를 셀프 조인으로 해결해 보면 다음과 같다. "자신과 상위, 차상위 관리자를 같은 줄에 표시하라." 이 문제를 해결하기 위해서는 FROM 절에 사원 테이블을 두 번 사용해야 한다.

셀프 조인은 동일한 테이블 이지만 위 그림과 같이 개념적으로는 두 개의 서로 다른 테이블을 사용하는 것과 동일하다. 동일 테이블을 다른 테이블인 것처럼 처리하기 위해 테이블 별칭을 사용한다. 여기서는 E1, E2 테이블 별칭을 사용하였다. 차상위 관리자를 구하기 위해서 E1.관리자 = E2.사원 조건을 사용한다.
4절 서브쿼리
서브쿼리란 하나의 sql문 안에 포함되어 있는 또 다른 sql문을 말하낟. 서브쿼리는 알려지지 않은 기준을 이용한 검색을 위해 사용하낟. 서브쿼리는 다음그림과 같이 메인 쿼리가 서브 쿼리를 포함하는 종속적인 관계이다.
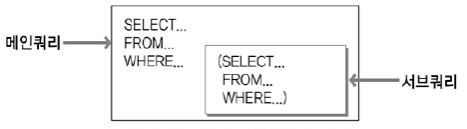
조인은 조인에 참여하는 모든 테이블이 대등한 관계에 있기 때문에 조인에 참여하는 모든 테이블의 칼럼을 어느 위치에서라도 자유롭게 사용할 수 있다. 그러나 서브쿼리는 메인쿼리의 칼럼을 모두 사용할 수 있지만 메인쿼리는 서브쿼리의 칼럼을 사용할 수 없다. 질의 결과에 서브쿼리 칼럼을 표시해야 한다면 조인 방식으로 변환하거나 함수, 스칼라 서브쿼리 등을 사용해야 한다.
조인은 집합간의 곱의 관계이다. 즉, 1:1 관계의 테이블이 조인하면 1(=1*1)레벨의 집합이 생성되고, 1:M 관계의 테이블을 조인하면 M(=1*M)레벨의 집합이 생성된다. 그리고 M:N 관계의 테이블을 조인하면 MN(=M*N) 레벨의 집합이 결과로서 생성된다. 예를 들어 조직(1)과 사원(M) 테이블을 조인하면 결과는 사원레벨(M)의 집합이 생성된다. 그러나 서브쿼리는 서브쿼리 레벨과는 상관없이 항상 메인쿼리 레벨로 결과 집합이 생성된다. 예를 들어, 메인쿼리로 조직(1), 서브쿼리로 사원(M) 테이블을 사용하면 결과집합은 조직(1) 레벨이 된다.
SQL 문에서 서브쿼리 방식을 사용해야 할 때 잘못 판단하여 조인 방식을 사용하는 경우가 있다. 예를들어, 결과는 조직 레벨이고 사원테이블에서 체크해야 할 조건이 존재한다고 가정하다. 이런 상황에서 SQL 문을 작성할 때 조인을 사용한다면 결과 집합은 사원(M) 레벨이 될 것이다. 이렇게 되면 원하는 결과가 아니기 때문에 SQL 문에 DISTINCT를 추가해서 결과를 다시 조직(1) 레벨로 만든다. 이와같은 상황에서는 조인 방식이 아니라 서브쿼리 방식을 사용해야 한다. 메인쿼리로 조직을 사용하고 서브쿼리로 사원 테이블을 사용하면 결과 집합은 조직레벨이 되기 때문에 원하는 결과가 된다.
서브쿼리를 사용할 때 다음 사항에 주의해야 한다.
1. 서브쿼리를 괄호로 감싸서 사용한다.
2. 서브쿼리는 단일행 또는 복수행 비교 연산자와 함께 사용 가능하다. 단일행 비교 연산자는 서브쿼리의 결과가 반드시 1건 이하이어야 하고 복수 행 비교 연산자는 서브쿼리의 결과 건수와 상관없다.
3. 서브쿼리에서는 ORDER BY를 사용하지 못한다. ORDER BY 적은 SELECT절에서 오직 한 개만 올 수 있기 때문에 ORDER BY절은 메인 쿼리의 마지막 문장에 위치해야 한다.
서브쿼리가 SQL 문에서 사용이 가능한 곳은 다음과 같다.
- SELECT 절
- FROM 절
- WHERE 절
- HAVING 절
- ORDER BY 절
- INSERT문의 VALUES 절
- UPDATE 문의 SET 절
서브쿼리의 종류는 동작하는 방식이나 반환되는 데이터의 형태에 따라 분류할 수 있다. 동작하는 방식에 따라 서브쿼리를 분류하면 다음표과 같이 두 가지로 나눌 수 있다.

서브쿼리는 메인쿼리 안에 포하된 종속적인 관계이기 때무넹 논리적인 실행순서는 항상 메인쿼리에서 읽혀진 데이터에 대해 서브쿼리에서 해당 조건이 만족한지를 확인하는 방식으로 수행되어야 한다. 그러나 실제 서브쿼리의 실행순서는 상황에 따라 달라질 수 있다.
반환되는 데이터의 형태에 따라 서브쿼리는 다음과 같이 세가지로 분류된다.

1. 단일 행 서브쿼리
서브쿼리가 단일 행 비교 연산자(=, <, <=, >, >=, <>) 와 함께 사용할 때는 서브쿼리의 결과 건수가 반드시 1건 이하이어야 한다. 만약, 서브쿼리의 결과 건수가 2건 이상을 반환하면 SQL 문은 실행시간 오류가 발생한다. 이런 종류의 오류는 컴파일 할 때는 알 수 없는 오류이다.
2. 다중행 서브쿼리
서브쿼리의 결과가 2건 이상 반환될 수 있다면 반드시 다중 행 비교 연산자(IN, ALL, ANY, SOME)와 함께 사용해야 한다. 그렇지 않으면 SQL문은 오류를 반환한다.
- IN (서브쿼리) : 서브쿼리의 결과에 존재하는 임의의 값과 동일한 조건을 의미한다.
- 비료연산자 ALL(서브쿼리) : 서브쿼리의 결과에 존재하는 모든 값을 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 모든 결과 값을 만족해야 하므로, 서브쿼리결과의 최대값보다 큰 모든 건이 조건을 만족한다.
- 비교연산자 ANY(서브쿼리) : 서브 쿼리의 결과에 존재하는 어느 하나의 값이라도 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 값들중 어떤 값이라도 만족하면 되므로, 서브쿼리의 결과의 최소값보다 큰 모든 건이 조건을 만족한다.
- EXISTS (서브쿼리) : 서브쿼리의 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건을 의미한다. 조건을 만족하는 건이 여러건이더라도 1건만 찾으면 더 이상 검색하지 않는다.
3. 다중 칼럼 서브쿼리
다중칼럼 서브쿼리는 서브쿼리의 결과로 여러개의 칼럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미.
4. 연관 서브쿼리
연관 서브쿼리는 서브쿼리 내에 메인쿼리 칼럼이 사용된 서브쿼리이다.
5. 그 밖의 위치에서 사용하는 서브쿼리
가. SELECT절에 사용(스칼라 서브쿼리). 스칼라 서브쿼리는 한행, 한 칼럼만을 반환하는 서브쿼리를 말한다. 스칼라 서브쿼리는 칼럼을 쓸 수 있는 대부분의 곳에서 사용할 수 있다.
나. FROM절에서 서브쿼리 사용하기(인라인 뷰)
FROM 절에는 테이블 명이 오도록 되어있다. 그런데 서브쿼리가 FROM 절에 사용되면 어떻게 될까? 서브쿼리의 결과가 마치 실행시에 동적으로 생성된 테이블인것 처럼 사용할 수 있
다. 인라인 뷰는 SQL 문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다. 그래서 일반적인 뷰를 정적뷰 라고 하고 인라인 뷰를 동적뷰 라고도 한다. 인라인뷰는 테이블 명이 올 수 있는 곳에서 사용할 수 있다. 서브쿼리의 칼럼은 메인쿼리에서 사용할 수 없다고 했다. 그러나 인라인 뷰는 동적으로 생성된 테이블이다. 인라인 뷰를 사용하는 것은 조인 방식을 사용하는 것과 같다. 그렇기 때문에 인라인 뷰의 칼럼은 SQL 문을 자유롭게 참조할 수 있다.
다. HAVING 절에서 서브쿼리 사용
HAVING절은 그룹함수와 함께 사용될 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해서 사용한다.
라. UPDATE문의 SET절에서 사용
마. INSERT문의 VALUES절에서 사용
6. VIEW
테이블은 실제로 데이터를 가지고 있는 반면, 뷰는 실제 데이터를 가지고 있지 않다. 뷰는 단지 뷰정의(VIEW DEFINITION)만을 가지고 있다. 질의에서 뷰가 사용되면 뷰 정의를 참조해서 DBMS 내부적으로 질의를 재작성 하여 질의를 수행한다. 뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블 이라고도 한다.
뷰 사용의 장점

뷰는 다음과 같이 create view문을 통해서 생성할 수 있다.
두개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법중에 또 다른 방법이 있는데 그 방법이 바로 집합연산자를 사용하는 방법이다. 조인에서는 FROM절에 검색하고자 하는 테이블을 나열하고, WHERE 절에 조인 조건을 기술하여 원하는 데이터를 조회할 수 있었다. 하지만 집합 연산자는 여러 개의 질의의 결과를 연결하여 하나로 결합하는 방식을 사용한다. 즉 집합연산자는 2개 이상의 질의 결과를 하나의 결과로 만들어 준다.
집합연산자를 사용하기 위해서는 다음 제약조건을 만족해야 한다. SELECT 절의 칼럼수가 동일하고 SELECT 절의 동일 위치에 존재하는 칼럼의 데이터 타입이 상호 호환가능해야 한다. 그렇지 않으면 데이터베이스가 오류를 반환.
집합 연산자의 종류
- UNION : 여러 개의 SQL 문의 결과에 대한 합집합으로 결과에서 모든 중복된 행은 하나의 행으로 만든다.
- UNION ALL : 여러 개의 SQL 문의 결과에 대한 합집합으로 중복된 행도 그대로 결과로 표시된다. 즉, 단순히 결과만 합쳐놓은 것이다. 일반적으로 여러 질의 결과가 상호 배타적인 일때 많이 사용한다. 개별 SQL 문의 결과가 서로 중복되지 않는 경우, UNION과 결과가 동일 하다.
- INTERSECT : 여러 개의 SQL 문의 결과에 대한 교집합이다. 중복된 행은 하나의 행으로 만든다.
- EXCEPT : 앞의 SQL 문의 결과에서 뒤의 SQL 문의 결과에 대한 차집합이다. 중복된 행은 하나의 행으로 만든다.
집합연산자는 개별 SQL문의 결과 집합에 대해 합집합, 교집합, 차집합으로 집합간의 관계를 가지고 작업을 한다.
집합 연산자를 사용하여 만들어지는 SQL문의 형태는 다음과 같다.
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명1
[WHERE 조건식 ]
[[GROUP BY 칼럼(Column)이나 표현식
[HAVING 그룹조건식 ] ]
집합 연산자
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명2
[WHERE 조건식 ]
[[GROUP BY 칼럼(Column)이나 표현식
[HAVING 그룹조건식 ] ]
[ORDER BY 1, 2 [ASC또는 DESC ] ;
----------------------------------------------------------
SELECT PLAYER_NAME 선수명, BACK_NO 백넘버
FROM PLAYER
WHERE TEAM_ID = 'K02'
UNION
SELECT PLAYER_NAME 선수명, BACK_NO 백넘버
FROM PLAYER
WHERE TEAM_ID = 'K07' ORDER BY 1;
|
집합연산자는 사용상의 제약조건을 만족한다면 어떤 형태의 SELECT문이라도 이용할 수 있다. 집합연산자는 여러개의 SELECT 문을 연결하는 것에 지나지 않는다. ORDER BY는 집합 연산을 적용한 최종결과에 대한 정렬처리이므로 가장 마지막 줄에 한번만 기술한다.
3절 계층형 질의와 셀프 조인
1. 계층형 질의
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의(HIREARCHICAL QUERY)를 사용한다. 계층형 데이터란 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터를 말한다. 예를 들어, 사원 테이블에서는 사원들 사이에 상위 사원(관리자)과 하위 사원 관계가 존재하고 조직 테이블에서는 조직들 사이에 상위 조직과 하위 조직 관계가 존재한다. 엔터티를 순환관계 데이터 모델로 설계할 경우 계층형 데이터가 발생한다. 순환관계 데이터 모델의 예로는 조직, 사원, 메뉴 등이 있다.
위 그림은 사원에 대한 순환관계 데이터 모델을 표현한 것이다. (2)계층형 구조에서 A의 하위 사원은 B, C이고 B 밑에는 사위 사원이 없고 C의 하위 사원은 D, E가 있다. 계층형 구조를 데이터로 표현한 것이 (3) 샘플 데이터 이다.
오라클은 계층형 질의를 지원하기 위해서 다름과 같은 계층형 질의 구문을 제공한다.
SELECT ...
FROM 테이블
WHERE condition AND condition...
START WITH condition
CONNECT BY [NOCYCLE] condition AND condition...
[ORDER SIBLINGS BY column, column, ...]
- START WITH 절은 계층 구조 전개의 시작 위치를 지정하는 구문이다. 즉 루트 데이터를 지정한다.
- CONNECT BY 절은 다음에 전개될 자식 데이터를 지정하는 구문이다. 자식 데이터는 CONNECT BY 절에 주어진 조건을 만족해야 한다.(조인)
-PRIOR : CONNECT BY 절에 사용되며, 현재 읽은 칼럼을 지정한다. PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 부모 데이터에서 자식데이터 (부모 -> 자식) 방향으로 전개하는 순방향 전개를 한다. 그리고 PRIOR 부모 = 자식 형태를 사용하면 반대로 자식 데이터에서 부모데이터 (자식 -> 부모) 방향으로 전개하는 역방향 전개를 한다.
- NOCYCLE : 데이터를 전개하면서 이미 나타났던 동일한 데이터가 전개 중에 다시 나타난다면 이것을 가리켜 사이틀이 형성되었다라고 말한다. 사이클이 발생한 데이터는 런타임 오류가 발생한다. 그렇지만 NOCYCLE를 추가하면 사이클이 발생한 이후의 데이터는 전개하지 않는다.
- ORDER SIBLINGS BY : 형제 노드(동일 LEVEL) 사이에서 절렬을 수행한다.
- WHERE : 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출한다. (필터링)
ORACLE 은 계층형 질의를 사용할 때 다음과 같은 가상칼럼(PSUDO COLUMN)을 제공한다.
2. 셀프조인
셀프조인이란 동일 테이블 사이의 조인을 말한다. 따라서 FROM절에 동일 테이블이 두 번 이상 나타난다. 동일 테이블 사이의 조이능ㄹ 수행하면 테이블과 칼럼 이름이 모두 동일하기 때문에 식별을 위해 반드시 테이블 별칭을 사용해야 한다. 그리고 칼럼에도 모두 테이블 별칭을 사용해서 어느 테이블의 칼럼인지 식별해줘야 한다. 이외 사항은 조인과 동일하다.
셀프 조인에 대한 기본적인 사용법은 다음과 같다.
SELECT ALIAS명1.칼럼명, ALIAS명2.칼럼명, ...
FROM 테이블1 ALIAS명1, 테이블2 ALIAS명2
WHERE ALIAS명1.칼럼명2 = ALIAS명2.칼럼명1;
|
SELECT WORKER.ID 사원번호, WORKER.NAME 사원명, MANAGER.NAME 관리자명
FROM EMP WORKER, EMP MANAGER
WHERE WORKER.MGR = MANAGER.ID;
|
계층형 질의에서 살펴보았던 사원이라는 테이블 속에는 사원과 관리자가 모두 하나의 사원이라는 개념으로 동일시하여 같이 입력되어 있다. 이것을 이용해서 다음 문제를 셀프 조인으로 해결해 보면 다음과 같다. "자신과 상위, 차상위 관리자를 같은 줄에 표시하라." 이 문제를 해결하기 위해서는 FROM 절에 사원 테이블을 두 번 사용해야 한다.
셀프 조인은 동일한 테이블 이지만 위 그림과 같이 개념적으로는 두 개의 서로 다른 테이블을 사용하는 것과 동일하다. 동일 테이블을 다른 테이블인 것처럼 처리하기 위해 테이블 별칭을 사용한다. 여기서는 E1, E2 테이블 별칭을 사용하였다. 차상위 관리자를 구하기 위해서 E1.관리자 = E2.사원 조건을 사용한다.
4절 서브쿼리
서브쿼리란 하나의 sql문 안에 포함되어 있는 또 다른 sql문을 말하낟. 서브쿼리는 알려지지 않은 기준을 이용한 검색을 위해 사용하낟. 서브쿼리는 다음그림과 같이 메인 쿼리가 서브 쿼리를 포함하는 종속적인 관계이다.
조인은 조인에 참여하는 모든 테이블이 대등한 관계에 있기 때문에 조인에 참여하는 모든 테이블의 칼럼을 어느 위치에서라도 자유롭게 사용할 수 있다. 그러나 서브쿼리는 메인쿼리의 칼럼을 모두 사용할 수 있지만 메인쿼리는 서브쿼리의 칼럼을 사용할 수 없다. 질의 결과에 서브쿼리 칼럼을 표시해야 한다면 조인 방식으로 변환하거나 함수, 스칼라 서브쿼리 등을 사용해야 한다.
조인은 집합간의 곱의 관계이다. 즉, 1:1 관계의 테이블이 조인하면 1(=1*1)레벨의 집합이 생성되고, 1:M 관계의 테이블을 조인하면 M(=1*M)레벨의 집합이 생성된다. 그리고 M:N 관계의 테이블을 조인하면 MN(=M*N) 레벨의 집합이 결과로서 생성된다. 예를 들어 조직(1)과 사원(M) 테이블을 조인하면 결과는 사원레벨(M)의 집합이 생성된다. 그러나 서브쿼리는 서브쿼리 레벨과는 상관없이 항상 메인쿼리 레벨로 결과 집합이 생성된다. 예를 들어, 메인쿼리로 조직(1), 서브쿼리로 사원(M) 테이블을 사용하면 결과집합은 조직(1) 레벨이 된다.
SQL 문에서 서브쿼리 방식을 사용해야 할 때 잘못 판단하여 조인 방식을 사용하는 경우가 있다. 예를들어, 결과는 조직 레벨이고 사원테이블에서 체크해야 할 조건이 존재한다고 가정하다. 이런 상황에서 SQL 문을 작성할 때 조인을 사용한다면 결과 집합은 사원(M) 레벨이 될 것이다. 이렇게 되면 원하는 결과가 아니기 때문에 SQL 문에 DISTINCT를 추가해서 결과를 다시 조직(1) 레벨로 만든다. 이와같은 상황에서는 조인 방식이 아니라 서브쿼리 방식을 사용해야 한다. 메인쿼리로 조직을 사용하고 서브쿼리로 사원 테이블을 사용하면 결과 집합은 조직레벨이 되기 때문에 원하는 결과가 된다.
서브쿼리를 사용할 때 다음 사항에 주의해야 한다.
1. 서브쿼리를 괄호로 감싸서 사용한다.
2. 서브쿼리는 단일행 또는 복수행 비교 연산자와 함께 사용 가능하다. 단일행 비교 연산자는 서브쿼리의 결과가 반드시 1건 이하이어야 하고 복수 행 비교 연산자는 서브쿼리의 결과 건수와 상관없다.
3. 서브쿼리에서는 ORDER BY를 사용하지 못한다. ORDER BY 적은 SELECT절에서 오직 한 개만 올 수 있기 때문에 ORDER BY절은 메인 쿼리의 마지막 문장에 위치해야 한다.
서브쿼리가 SQL 문에서 사용이 가능한 곳은 다음과 같다.
- SELECT 절
- FROM 절
- WHERE 절
- HAVING 절
- ORDER BY 절
- INSERT문의 VALUES 절
- UPDATE 문의 SET 절
서브쿼리의 종류는 동작하는 방식이나 반환되는 데이터의 형태에 따라 분류할 수 있다. 동작하는 방식에 따라 서브쿼리를 분류하면 다음표과 같이 두 가지로 나눌 수 있다.
서브쿼리는 메인쿼리 안에 포하된 종속적인 관계이기 때무넹 논리적인 실행순서는 항상 메인쿼리에서 읽혀진 데이터에 대해 서브쿼리에서 해당 조건이 만족한지를 확인하는 방식으로 수행되어야 한다. 그러나 실제 서브쿼리의 실행순서는 상황에 따라 달라질 수 있다.
반환되는 데이터의 형태에 따라 서브쿼리는 다음과 같이 세가지로 분류된다.
1. 단일 행 서브쿼리
서브쿼리가 단일 행 비교 연산자(=, <, <=, >, >=, <>) 와 함께 사용할 때는 서브쿼리의 결과 건수가 반드시 1건 이하이어야 한다. 만약, 서브쿼리의 결과 건수가 2건 이상을 반환하면 SQL 문은 실행시간 오류가 발생한다. 이런 종류의 오류는 컴파일 할 때는 알 수 없는 오류이다.
2. 다중행 서브쿼리
서브쿼리의 결과가 2건 이상 반환될 수 있다면 반드시 다중 행 비교 연산자(IN, ALL, ANY, SOME)와 함께 사용해야 한다. 그렇지 않으면 SQL문은 오류를 반환한다.
- IN (서브쿼리) : 서브쿼리의 결과에 존재하는 임의의 값과 동일한 조건을 의미한다.
- 비료연산자 ALL(서브쿼리) : 서브쿼리의 결과에 존재하는 모든 값을 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 모든 결과 값을 만족해야 하므로, 서브쿼리결과의 최대값보다 큰 모든 건이 조건을 만족한다.
- 비교연산자 ANY(서브쿼리) : 서브 쿼리의 결과에 존재하는 어느 하나의 값이라도 만족하는 조건을 의미한다. 비교 연산자로 ">" 를 사용했다면 메인 쿼리는 서브쿼리의 값들중 어떤 값이라도 만족하면 되므로, 서브쿼리의 결과의 최소값보다 큰 모든 건이 조건을 만족한다.
- EXISTS (서브쿼리) : 서브쿼리의 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건을 의미한다. 조건을 만족하는 건이 여러건이더라도 1건만 찾으면 더 이상 검색하지 않는다.
3. 다중 칼럼 서브쿼리
다중칼럼 서브쿼리는 서브쿼리의 결과로 여러개의 칼럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미.
4. 연관 서브쿼리
연관 서브쿼리는 서브쿼리 내에 메인쿼리 칼럼이 사용된 서브쿼리이다.
5. 그 밖의 위치에서 사용하는 서브쿼리
가. SELECT절에 사용(스칼라 서브쿼리). 스칼라 서브쿼리는 한행, 한 칼럼만을 반환하는 서브쿼리를 말한다. 스칼라 서브쿼리는 칼럼을 쓸 수 있는 대부분의 곳에서 사용할 수 있다.
나. FROM절에서 서브쿼리 사용하기(인라인 뷰)
FROM 절에는 테이블 명이 오도록 되어있다. 그런데 서브쿼리가 FROM 절에 사용되면 어떻게 될까? 서브쿼리의 결과가 마치 실행시에 동적으로 생성된 테이블인것 처럼 사용할 수 있
다. 인라인 뷰는 SQL 문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다. 그래서 일반적인 뷰를 정적뷰 라고 하고 인라인 뷰를 동적뷰 라고도 한다. 인라인뷰는 테이블 명이 올 수 있는 곳에서 사용할 수 있다. 서브쿼리의 칼럼은 메인쿼리에서 사용할 수 없다고 했다. 그러나 인라인 뷰는 동적으로 생성된 테이블이다. 인라인 뷰를 사용하는 것은 조인 방식을 사용하는 것과 같다. 그렇기 때문에 인라인 뷰의 칼럼은 SQL 문을 자유롭게 참조할 수 있다.
다. HAVING 절에서 서브쿼리 사용
HAVING절은 그룹함수와 함께 사용될 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해서 사용한다.
라. UPDATE문의 SET절에서 사용
마. INSERT문의 VALUES절에서 사용
6. VIEW
테이블은 실제로 데이터를 가지고 있는 반면, 뷰는 실제 데이터를 가지고 있지 않다. 뷰는 단지 뷰정의(VIEW DEFINITION)만을 가지고 있다. 질의에서 뷰가 사용되면 뷰 정의를 참조해서 DBMS 내부적으로 질의를 재작성 하여 질의를 수행한다. 뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블 이라고도 한다.
뷰 사용의 장점
뷰는 다음과 같이 create view문을 통해서 생성할 수 있다.
CREATE VIEW V_PLAYER_TEAM
AS SELECT P.PLAYER_NAME, P.POSITION, P.BACK_NO, P.TEAM_ID, T.TEAM_NAME
FROM PLAYER P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID;
|
2013년 2월 24일 일요일
[펌]오라클 함수 모음
출처 : http://bencrow.tistory.com/entry/%EC%98%A4%EB%9D%BC%ED%81%B4-%ED%95%A8%EC%88%98-%EB%AA%A8%EC%9D%8C
* 단일 행 함수
-함수가 정의된 SQL문이 실행될 때 각각의 ROW에 대해 수행되며 ROW 당 하나의 결과를 리턴 해줍니다.
-인수로는 상수,변수,표현식들이 사용될 수 있습니다.
-SELECT,WHERE,ORDER BY 절에 사용할 수 있습니다.
구 분 | 함수 | 내 용
---------------------------------------------------------------------------------------
LOWER 모든 문자를 소문자로
UPPER 모든 문자를 대문자로
INITCAP 첫 글자는 대문자,나머지는 소문자로
CANCAT 첫 번째 문자와 두 번째 문자를 연결
SUBSTR 문자의 길이를 리턴할 때
LENGTH 문자의 길이를 리턴할 때
NVL 널값을 다른 값으로 대체할 때
NVL2 조건에 의해 널값을 다른 값으로 대체할 때
SUBSTR 특정 문자의 문자열중 필요 부분만 선별하여 사용
문자 RTRIM 서브 스트림의 정확한 위치와 길이를 요구(오른쪽)
함수 LTRIM 서브 스트림의 정확한 위치와 길이를 요구(왼쪽)
RPAD 문자열을 제외한 공간에 지정한 문자열로 대체(오른쪽)
LPAD 문자열을 제외한 공간에 지정한 문자열로 대체(왼쪽)
TRANSLATE 첫 문자는 탐색집합의 첫 문자로 대체(2번째도 동일)
REPLACE 특정 문자열을 다른 문자열로 대체
SOUNDX 같은 단어 또는 유사한 사운드 단어를 음성학적으로
LENGTH 문자의 실제 길이를 변환할 때
LENGTHB 문자열의 실제 길이를 변환할 때
INTSTR 문자열 내의 특정 스트림의 위치
NULLIF 조건이 같으면 NULL,다르면 지정된 값을 리턴할 때
COALESCE 조건에 따라 여러 가지 값을 리턴할 때
-----------------------------------------------------------------------------------------
시스템 USER 현재 DB 사용자
함수 USERID 현재 DB 사용자에게 할당되는 사용자번호
-----------------------------------------------------------------------------------------
*문자함수의 예제
EX) -2개의 문자값을 결합합니다.
SQL>SELECT CONCAT(CONCAT(ename, ' is a '),job)
FROM emp;
CONCAT(CONCAT(ENAME,'ISA
---------------------------------
SMITH is a CLERK
ALLEN is a SALESMAN
-정의된 문장 단어의 첫 번째 문자를 대문자로 변환
SOL> SELECT INITCAP( 'the soap') FROM DUAL;
INITCAP(
-----------
The Soap
-정의된 문장의 왼쪽 나머지 공간을 지정한 문자로 채웁니다.
SQL> SELECT LPAD( 'Page 1' , 15 , '*.') FROM DUAL;
LPAD( 'PAGE1',15
---------------------
*.*.*.*.*Page 1
-정의된 문장의 왼쪽부터 지정된 단어가 발견되면 제거합니다.
SQL> SELECT LTRIM( 'xyxXxyLAST WORD','xy') FROM DUAL;
LTRIM('XYXXX
-------------------
XxyLAST WORD
-정의된 문장에서 해당 문자가 발견되면 지정된 문자로 변경합니다.
SQL> SELECT REPLACE( 'JACK and JUE' , 'J' , 'BL') FROM DUAL;
REPLACE( 'JACKA
-----------------------
BLACK and BLUE
-정의된 문자의 오른쪽 나머지 공간을 지정한 문자로 채웁니다.
SQL> SELECT RPAD(ename, 11 ,'ab' ) FROM emp WHERE ename = 'TURNER' ;
RPAD(ENAME , 11 ,'AB')
---------------------------
TURNERababa
-정의된 문자의 오른쪽부터 지정된 단어가 발견되면 제거합니다.
SQL> SELECT RTRIM( 'TURNERyxXxy' , 'xy') FROM DUAL ;
RTRIM( 'TU
-------------
TURNERyxX
-정의된 문장의 지정된 위치부터 해당 길이 만큼만 추출합니다.
SQL> SELECT SUBSTR( 'ABCDEFG' , 3 , 2 ) FROM DUAL ;
SU
-------
CD
-정의된 문장의 뒤에서부터 지정된 위치의 해당 길이 만큼만 추출합니다.
SQL> SELECT SUBSTR ( 'ABCDEFG' , -3 , 2 ) FROM DUAL ;
SU
--------
EF
-문자 'Q'를 ASCII 코드로 변환합니다.
SQL> SELECT ASCII ( 'Q' ) FROM DUAL ;
ASCII ( 'Q' )
---------------
81
-정의된 문장에서 지정된 위치에 존재하는 문자의 위치 값을 찾아 줍니다.
SQL> SELECT INSTR ( 'CORPORATE FLOOR' , 'OR' ,3 ,2 ) FROM DUAL ;
INSTR ( 'CORPORATEFLOOR' , 'OR' , 3 , 2 )
---------------------------------------------
14
-정의된 문장의 길이를 변환합니다.
SQL> SELECT LENGTHB ( '가나다라마바사') FROM DUAL ;
LENGTH( '가나다라마바사' )
---------------------------
14
-정의된 단어 중에 가장 높은 값을 찾아줍니다.
SQL> SELECT GREATEST ( 'HARRY' , 'HARIOT' ,'HALORD' ) FROM DUAL ;
GREAT
---------
HARRY
-정의한 컬럼이 NULL이면 지정한 값으로 대체합니다.
SQL> SELECT NVL (sal , 0 ) , NVL( ename , '*' ) , NVL(hiredate , '01-JAN-02' ) FROM emp ;
NVL(SAL , 0 ) NVL(ENAME , NVL(HIRE
------------------------------------------------
800 SMITH 80/12/17
*시스템 함수
-현재 어떤 사용자로 데이터 베이스에 접속하였는지 알 수 있습니다.
SQL> SELECT USER FROM dual ;
USER
-------
SCOTT
* 숫자함수/날짜함수
------------------------------------------------------------------------------
구 분 함 수 내 용
------------------------------------------------------------------------------
ROUND 해당 소수점 자리에서 반올림할 때
TRUNC 해당 소수점 자리에서 절삭할 때
MOD(m/n) m을 n으로 나누고 남은 나머지를 리턴할 때
ABS 숫자 값을 절대값으로 바꾼다
SIGN 숫자가 양수:+1, 음수:-1, 0:0
숫자함수 FLOOR 실수값을 정수값으로
CEIL 그 수보다 가장 크거나 작은값을 리턴
POWER 해당 수에 대한 지수값을 표현
LOG 로그값으로 변환
SIN SIN값
COS COS값
TAN TAN값
------------------------------------------------------------------------------
SYSDATE 현재 시스템 날짜를 보여줄 때
ADD_MONTHS 지정한 날짜에 몇 월을 추가한 결과의 월을 계산할 때
LAST_DAY 해당 월의 마지막 날짜를 알고자 할 때
날짜함수 NEW_TIME 해당 표준시로 시간을 변환할 때
NEXT_DAY 해당 날짜의 다음 지정한 날짜로 현환할 때
NONTH_BETWEEN 지정된 월 간의 월수를 알고자 할 때
------------------------------------------------------------------------------
* 숫자함수 예제....
-정의된 값을 절대값으로 변환 합니다
SQL> SELECT ABS(-15) FROM DUAL ;
ABS(-15)
-----------
15
-정의된 값의 올림된 값으로 변환합니다
SQL> SELECT CEIL(15.7) FROM DUAL ;
CEIL(15.7)
-------------
16
-정의된 값의 내림된 값으로 변환합니다
SQL> SELECT FLOOR(15.7) FROM DUAL ;
FLOOR(15.7)
---------------
15
-정의된 산술식의 COSINE 값으로 변환합니다
SQL> SELECT COS(180*3.14/180) FROM DUAL ;
COS(180*3.14/180)
--------------------
-.99999873
-정의된 숫자의 지수승값을 계산합니다
SQL> SELECT EXP(4) FROM DUAL ;
EXP(4)
---------
54.59815
-뒤에 정의된 수로 앞에 정의된 수를 나눈 나머지 값을 반환합니다
SQL> SELECT MOD(11,4) FROM DUAL ;
MOD(11,4)
------------
3
-정의된 수를 지정한 자리 수에서 반올림합니다
SQL> SELECT ROUND(15.193 , 1) FROM DUAL ;
ROUND(15.193 , 1)
-------------------
15.2
-정의된 값이 음수이면 -1 , 0 이면 0, 양수이면 1을 리턴합니다
SQL> SELECT SIGN(-15) FROM DUAL ;
SIGN(-15)
------------
-1
-정의된 수를 지정한 자리 수 에서 절삭합니다
SQL> SELECT TRUNC(15.97 , 1) FROM DUAL ;
TRUNC(15.79 , 1)
-----------------
15.7
* 날짜 함수 예제
-현재 시스템 날짜를 제공합니다
SQL> SELECT SYSDATE FROM DUAL ;
SYSDATE
-----------
06/11/13
-해당 날짜에 지정한 달 수만큼 더합니다
SQL> SELECT HIREDATE , ADD_MONTHS(HIREDATE , 1)
FROM EMP WHERE EMPNO = 7782 ;
HIREDATE ADD_MONT
--------------------------
81/06/09 81/07/09
-정의된 날짜의 달에서 마지막 일이 몇 일인지 알 수 있습니다
SQL> SELECT HIREDATE , LAST_DAY(HIREDATE)
FROM EMP WHERE EMPNO = 7782 ;
HIREDATE LAST_DAY
--------------------------
81/06/09 81/06/30
-정의된 두 날짜간의 차이 값을 알 수 있습니다
SQL> SELECT HIREDATE , MONTHS_BETWEEN(SYSDATE , HIREDATE)
FROM EMP WHERE EMPNO = 7782 ;
HIREDATE MONTHS_BETWEEN(SYSDATE , HIREDATE)
------------------------------------------------------------
81/06/09 252.930883
-정의된 날짜를 녀도 값을 기준으로 반올림 합니다
SQL > SELECT
ROUND(TO_DATE(' 27-OCT-98' , 'DD-MON-YY' ) ,
'YEAT' ) FROM DUAL ;
ROUND(TO
------------
99/01/01
변환 함수
---------------------------------------------------------------------------
구 분 함 수 내 용
---------------------------------------------------------------------------
TO_CHAR 숫자,날짜 타입의 Data를 varchar2타입으로 변환
변환함수 TO_NUMBER 숫자를 포함하는 문자 String을 number 타입으로 변환
TO_DATE 문자 String을 날짜 타입으로 변환
---------------------------------------------------------------------------
*날짜 형식 요소
---------------------------------------------------------------------------
형식 요소 설 명
---------------------------------------------------------------------------
MM 달 수(ex : 10)
MON 월 이름을 3자리 문자로 표현(ex : JAN , FEB , MAR 등)
MONTH 월 이름(ex : JANUARY,FEBUARY,MARCH 등)
DD 날짜 (ex : 14)
D 주의 일수 (ex : 4)
DY 요일 이름을 3자리 문자로 표현(ex : SUN , MON , TUE 등)
DAY 요일 이름(ex : SUNDAY , MONDAY 등)
YYYY 년도 4자리 수 (ex : 2002)
YY 년도의 마지막 2자리(ex : 02)
----------------------------------------------------------------------------
*시간 형식 요소
----------------------------------------------------------------------------
형식 요소 설 명
----------------------------------------------------------------------------
9 숫자(ex : 9999 → 1534)
0 자리 수가 비면 0으로 채워줌 ( ex : 09999 → 01534 )
$ 금액에 $를 표시해줌 (ex : $99999 → $1534 )
. 명시한 위치에 소수점을 표시함 (ex : 99999.99 → 1534.00 )
, 명시한 위치에 콤마를 표시함 (ex : 999,999 → 1,534 )
----------------------------------------------------------------------------
변환 함수 예제들.....
-현재 날짜가 한 주에서 몇번째 일인지 알 수 있습니다
SQL> SELECT SYSDATE , TO_CHAR ( SYSDATE , 'D' )
FROM dual ;
SYSDATE TO_CHAR
--------------------------
02/09/26 5
-정의된 날짜의 출력 포맷을 DD-MM-YY로 출력합니다
SQL> SELECT ename , TO_CHAR(hiredate , 'DD-MM-YY' ) HIREDATE
FROM emp ;
ENAME TO_CHAR(hiredate , 'DD-MM-YY' )
------------------------------------------------
SMITH 17 11 90
ALLY 20 02 91
......................
-일자를 출력할 때 0 값을 제거합니다(09 → 9 , 01 → 1)
SQL> SELECT ename , TO_CHAR (hiredate , 'fmDD-MM-YY' ) HIREDATE
FROM emp ;
ENAME TO_CHAR(hiredate , 'fmDD-MM-YY' )
---------------------------------------------------
....................................
MARTIN 9 09 91
....................................
-문자 100을 숫자값으로 출력합니다
SQL> SELECT TO_NUMBER ( '100' ) FROM dual ;
TO_NUMBER
--------------
100
-현재 시간을 AM , PM 표기법으로 출력합니다
SQL> SELECT TO_CHAR( SYSDATE , 'AM HH:MI ' )
FROM dual ;
TO_CHAR(
-----------
오전 10 : 10
-숫자값을 출력할 때 금액표시를 합니다
SQL> SELECT TO_CHAR( 12506 , '$9099,999' ) FROM dual ;
TO_CHAR(
-----------
$010,234
-정의된 날짜를 지정한 포맷으로 출력합니다
SQL> SELECT TO_DATE( '01-JUL-99' , 'DD-MM-YY' )
FROM dual ;
TO_DATE(
-----------
99/07/01
-정의된 시간을 지정한 포맷으로 출력합니다
SQL> SELECT TO_DATE( '01:30' , 'HH24:MI' ) FROM dual ;
TO_DATE
----------
13:30
단일행함수
* NVL2 ( Colum, Express1, Express2 )
-해당 컬럼이 null이면 Express-2 의 값을 , null이 아니면 Express-1의 값을 리턴해 줍니다.
오라클 이전 버전에서 사용되던 NVL함수는 정의된 컬럼의 값이 null인 경우 지정한 값으로
대체하는 기능을 가지고 있었습니다. 반대로, NVL2 함수는 정의된 컬럼의 값이 지정한
값인 경우 null값으로 대체된다.
NVL2 함수는 해당 컬럼이 null 값이 아니면 Express2의 값을 리턴해 주고 null 값이면
Express3의 값을 리턴해 주는 기능을 가지고 있습니다.
SQL> SELECT empno, ename, nv12( comm, comm.*1.1, 0 )
FROM emp ;
EMPNO ENAME COMM NVL2( COMM, COMM*1.1, 0 )
----------------------------------------------------------
7369 SMITH 0
7499 ALLEN 300 330
7521 WARD 500 550
7566 JONES 0
..............................................
->COMM이 null인 경우 null이 아닌 경우
* NULLIF ( Express1, Express2 )
-Express-1과 Express-2의 값을 비교하여 그 값이 같으면 null을 리턴하고 다르면 Express-1의
값을 리턴해 줍니다.
NULLIF 함수는 Express-1 과 Express-2 의 값을 비교하여 그 값이 같으면 null 값을 리턴하고
서로 다른 값을 가지고 있으면 Express-1의 값을 리턴해 주는 함수입니다.
LENGTH(first_name)의 값과 LENGTH(last_name)의 값을 NULLIF 함수로 비교하여 같으면
null 값을 화면에 출력하고 다르면 LENGTH(first_name)의 값을 화면에 출력합니다.
SQL> SELECT empno, ename, nullif( comm, 0 )
FROM emp ;
EMPNO ENAME COMM NULLIF( COMM, 0 )
--------------------------------------------------
7369 SMITH
7370 ALLEN 300 300
7521 WARD 500 500
7566 JONES
7654 MARTIN 1400 1400
.....................................
->COMM이 NULL이므로 NULL, COMM이 NULL이 아니므로 COMM값으로...
*COALLESCE 함수
이 함수는 EXPRESS-1의 값이 NULL값이 아니면 EXPRESS-1의 값을 화면에 출력해 주고
NULL 값이면 EXPRESS-2의 값을 EXPRESS-1의 값과 EXPRESS-2의 값모두 NULL이면
EXPRESS-N의 값을 화면에 출력해 주는 함수입니다. 문법에서 정의된 각 컬럼에서 NULL이
아닌 첫 번째 컬럼의 값을 돌려줍니다.
SQL> SELECT coalesce( comm,sal ) FROM emp ;
COALESCE( COMM,SAL )
-------------------------
800
300
SQL> SELECT coalesce ( comm, 100 ) FROM emp ;
COALESCE( COMM,100 )
-------------------------
100
300
500
->이 문법은 COALESCE([컬럼],[값]) 문법에서 정의된 컬럼이 NULL이면 정의된 값을
더한 결과를 돌려줍니다. 원래 NULL이지만 100을 더한 값이 출력됩니다.
*TRIM함수
이 함수는 오라클 8i 버전에서 추가된 함수이며 이전 버전에서 제공되던 LTRIM 함수와
RTRIM 함수를 결합한 형태의 함수입니다. TRIM 함수는 문자값의 왼쪽 또는 오른쪽 부분에
정의한 문자값이 존재하면 그 문자를 절삭시키는 기능을 가지고 있습니다. TRIM 함수는
3가지 종류의 기능을 가지고 있습니다.
-먼저,LEADING은 이전의 LTRIM 함수와 동일한 기능을 가지고 있습니다.정의된 컬럼의 값
왼쪽에 해당 문자열이 존재하면 문자값을 절삭시켜서 화면에 출력합니다.
SQL> SELECT ename, TRIM( LEADING 'A' FROM ename ) as TRIM
FROM emp
WHERE ename LIKE 'A%' ;
ENAME TRIM
-------------------------
ALLEN LLEN
ADAMS DAMS
-TRAILING은 이전의 RTRIM 함수의 기능을 가지고 있으며 컬럼값의 오른쪽에 존재하는 문자값을
절삭해줍니다.
SQL> SELECT ename, TRIM( TRAILING 'N' FROM ename ) as TRIM
FROM emp
WHERE ename LIKE '%N' ;
ENAME TRIM
---------------------
ALLEN ALLE
MARTIN MARTI
-BOTH는 왼쪽, 오른쪽에 해당 문자열이 있으면 절삭해 주는 기능을 가지고 있습니다.
SQL> SELECT ename, TRIM( BOTH 'A' FROM ename ) as TRIM
FROM emp
WHERE ename LIKE 'A%' ;
ENAME TRIM
--------------------
ALLEN LLEN
ADAMS DAMS
->ENAME 컬럼에서 마지막 문자가 'A'인 값은 발견되지 않았고 첫번째 문자가 'A'인
사원은 ALLEN과 ADAMS
피드 구독하기:
글 (Atom)